La pérdida de valor de las credenciales educativas en el mercado de trabajo Argentino 1995-2001. Una respuesta desde los métodos estadísticos.
En este trabajo se sostiene que durante la segunda mitad de la década de 1990 se desarrolló un proceso de pérdida de valor de las credenciales educativas de los trabajadores con nivel de estudios secundario completo o mayor. Como a su vez en el período se incrementó la desigualdad salarial se sostiene que lo que se observa es un fenómeno de dos aristas: de devaluación educativa y segmentación del mercado de trabajo. Para realizar estas afirmaciones se utilizan regresiones lineales múltiples para el cálculo de premios salariales. Dado que la fuente utilizada es una muestra y el universo es pequeño se utilizan pooles de datos para ampliar la cantidad de muestra disponible y mejorar las estimaciones. Se desarrolla una metodología cuyo objetivo es poder decidir desde el punto de vista estadístico si los pooles de datos pueden ser utilizados o no en cada problema de trabajo y como trabajar con ellos, y así poder utilizar los recursos disponibles bajo el control de métodos estadísticos.
Los docentes en la Encuesta Permanente de Hogares. Notas metodológicas para su identificación y estudio.
El estudio de los docentes como colectivo laboral en Argentina puede ser realizado con precisión a partir de los Censos Nacionales de Docentes. Estas fuentes de información son específicas del sector educativo y, por lo tanto, las más idóneas para la caracterización detallada de los cargos, horas, funciones, trayectorias y formación de los docentes. Sin embargo, sus principales limitaciones son la periodicidad decenal y las dificultades para comparar a los docentes con otros grupos laborales. La Encuesta Permanente de Hogares, fuente diseñada para caracterizar y monitorear la inserción laboral de la población, permite suplir las limitaciones mencionadas en el estudio de los ocupados en las actividades de enseñanza. Sin embargo, tiene ciertas características y limitaciones que resultan importantes tener en cuenta al utilizarla para estudiar el colectivo docente. Este artículo analiza la fuente en cuanto sus potencialidades para el estudio de este grupo laboral. Concluye que es consistente para el estudio de la evolución del empleo docente.
Especificación del modelo, datos faltantes y casos atípicos: la “trastienda” de una investigación basada en el análisis de la varianza.
El artículo está centrado en la discusión de aspectos metodológicos de la investigación de tesis de la autora. En el campo de los estudios sobre la distribución personal del ingreso y los mercados de trabajo resulta habitual el análisis de la regresión del ingreso personal contra diversos atributos de los perceptores y sus ocupaciones. Este análisis tiene por requisito la resolución de cuestiones referidas a: la definición del modelo en que estará basado, el tratamiento que se dará a los casos sin información y los procedimientos mediante los que se evaluará y, eventualmente, corregirá la influencia de los casos extremos sobre los parámetros estimados. El artículo refiere qué decisiones fueron tomadas en la investigación a este respecto, fundamentando las razones y describiendo su impacto sobre los resultados obtenidos.
¿Qué son los Indicadores? Perspectivas y usos diferentes.
El presente artículo tiene como objetivo presentar las diferentes perspectivas y usos de los indicadores, por un lado, desde las ciencias sociales y por otro desde lo que se denominó “Movimiento de Indicadores Sociales”. En términos generales, el uso de los indicadores ha sido utilizado desde el enfoque de las ciencias sociales para medir empíricamente conceptos teóricos que permitan el abordaje empírico a los fenómenos sociales. Sin embargo, los indicadores son también utilizados desde una perspectiva más pragmática, principalmente por los organismos de estadística y organismos internacionales. A través del artículo se presentan los diferentes recorridos realizados por las perspectivas mencionadas. En la primera parte se describe la medición empírica de conceptos a través de indicadores en los principales referentes de las ciencias sociales. En la segunda parte se describe el contexto de surgimiento y el desarrollo de lo que se denominó “Movimiento de Indicadores Sociales” como otra forma de aproximación al estudio de la realidad social a través de indicadores. En la tercera se problematiza las diferencias de ambas perspectivas en cuanto a los objetivos y el método que utilizan y se presenta como conclusión la importancia de vincular ambas perspectivas.
Aportes al estudio de la opinión pública en las elecciones presidenciales 2007 en Argentina.
El presente trabajo intenta explorar la creciente importancia que los estudios de opinión pública han comenzado a tener durante las últimas décadas. En este sentido, se busca brindar un aporte a la investigación dentro de una actividad que siempre ha estado más bien alejada del ámbito académico, en especial en los estudios relacionados con los procesos electorales. Asimismo, el trabajo intenta develar la notable injerencia que los medios de comunicación tienen en los procesos electorales de los últimos años, demostrándose que se trata de una tendencia que va tomando cada vez más impulso. Finalmente, se analizaran cuestiones que resultan un aporte para diagnosticar los cambios en las percepciones de la ciudadanía durante la etapa previa y posterior a una elección.
Construcción de un índice del nivel socioeconómico del hogar urbano en la República Argentina mediante el análisis de correspondencia múltiple y escalamiento óptimo.
El trabajo presenta la construcción de un índice que tiene como finalidad asignar a cada hogar urbano de la República Argentina un nivel socioeconómico. Se piensa al índice como una variable latente (no observable) y se aplica el análisis de correspondencia múltiple, método exploratorio de estadística multivariada, para obtener los ponderadores (pesos) de las modalidades de las doce variables seleccionadas.
El índice se compone de variables relativas a las características de la vivienda, la condición laboral y educativa del jefe de hogar y del cónyuge. La metodología se aplica a la Encuesta Nacional de Gasto de los Hogares 2012/2013 (Instituto Nacional de Estadísticas y Censos). Una vez estimados los puntajes de la variable latente para los hogares urbanos, se establecen los quintiles socioeconómicos y se asigna a cada hogar un quintil. Finalmente, se analizan las características de cada uno de los quintiles obtenidos y se indican las fortalezas y limitaciones de la metodología.
Orientaciones de futuro laboral y educativo de estudiantes secundarios. Análisis multivariado en un diseño muestral complejo.
En este artículo se analizan las orientaciones de futuro laboral y educativo de los estudiantes que a fines de 2008 cursaban el último año de estudio en las escuelas estatales de la Ciudad Autónoma de Buenos Aires. En primer lugar, se describen las orientaciones de futuro hallándose una prevalencia de proyectos educativo-laborales entre los estudiantes y una anticipación de obstáculos que resulta más pronunciada en el plano laboral que en el educativo. Luego, mediante un análisis de regresión logística multivariada, se compara la influencia relativa de distintos atributos sociales, escolares, biográficos y de la oferta educativa sobre los objetivos de tipo profesional. Entre los principales resultados se halla que las diferencias de género muestran contundencia en la priorización de un objetivo profesional. La modalidad del plan de estudios también emerge como un aspecto clave en los horizontes de futuro, observándose un hiato entre la formación bachiller-comercial y la técnica, donde prevalecen expectativas de inserción laboral directa luego del egreso. Otro hallazgo es que en el plano educativo los horizontes de profesionalización adquieren una difusión más amplia e independiente del origen social educacional, como reflejo de un contexto donde están dadas ciertas condiciones para el acceso masivo a la educación superior. Por otra parte, en el trabajo se enfatiza la importancia de considerar la complejidad del diseño muestral en la instancia de análisis de los datos. Para ello se comparan los resultados obtenidos con estimadores que consideran la complejidad de diseño muestral con otros “naive”, reflexionando acerca de las implicancias epistemológicas que esto conlleva en la puesta a prueba de hipótesis en el análisis bivariado y multivariado.
“Condiciones de socialización, entorno y trayectoria asociados a la reincidencia en el delito”.
En la actualidad el delito y la punición son analizados desde diferentes enfoques, ya que además de estar en crisis son temas a los cuales se les busca encontrar respuestas y soluciones. Es sabido entre los expertos que estudian estos tópicos que dentro de las cárceles la población es mayoritariamente joven, con bajos niveles de educación y provenientes de clases socioeconómicas medias/bajas y bajas, caracterizadas, entre otras cosas, por los bajos niveles de ingreso.
Teniendo en cuenta estas características podría pensarse que la vinculación explicativa de una conducta delictiva está dada por la asociación entre la condición de pobreza de un hogar y/o de sus integrantes y las probabilidades de comisión de delitos y la reincidencia en los mismos. Sin embargo, en este documento proponemos la existencia de una relación mucho más compleja. Por lo tanto, cabe preguntarse en relación al delito y a la reincidencia en el mismo, ¿qué tan asociados están esos factores a quienes incurren nuevamente en una conducta delictiva y al nivel de violencia al momento de perpetrar un delito?, finalmente, ¿qué factores son estos?
Para responder a estas preguntas se realizó un modelo de análisis multivariado basado en una regresión logística, en el cual se incorporaron variables relacionadas con los entornos o contextos de socialización temprana de los sujetos así como la trayectoria en instituciones como los institutos de menores. Los datos utilizados pertenecen a la Encuesta a Población en Reclusión de 2013, en la cual para Argentina se aplicaron más de mil encuestas personales a presos condenados por la justicia federal y ordinaria de la Capital así como por la justicia de la Provincia de Buenos Aires. Cabe destacar, además, que este fue un estudio que abarcó un conjunto de otros cinco países de la región: Brasil, Chile, El Salvador, México y Perú.
Un ejemplo de diseño cuasi experimental: uso de la regresión logística binaria en la construcción de un grupo de comparación para la evaluación de impacto de un programa social.
Este artículo trata acerca del empleo de la regresión logística binaria para la construcción de un grupo de comparación útil para la evaluación de impacto de un programa social. Se basa en una experiencia de aplicación real de tal procedimiento.
En la primera parte se aborda brevemente la problemática que plantea la implementación de diseños puramente experimentales en el caso de la evaluación de políticas públicas de contenido social y la alternativa de emplear modelos cuasi experimentales con un grupo de comparación construido estadísticamente. También se ponen en consideración algunas cuestiones inherentes a los diseños con doble medición, al tiempo que se abordan las dificultades que plantea la frecuente ausencia de una línea de base en el caso de los programas sociales. Asimismo, se explicitan los requisitos que debieran cumplimentar los grupos de comparación construidos mediante modelación estadística.
La segunda parte se refiere a las características del procedimiento estadístico empleado (la regresión logística binaria) y su utilidad específica para la obtención de grupos de comparación, con las limitaciones e inconvenientes que plantea, las alternativas posibles para sortearlos y los recaudos a adoptar. Finalmente, en la última parte se exponen los resultados provenientes del ejemplo de aplicación de este procedimiento conjuntamente con la interpretación de los mismos.
METODOLOGIA ESTADISTICA PARA LA ESTIMACION DE LAS SUPERFICIES SEMBRADAS CON CULTIVOS EXTENSIVOS - METODO DE SEGMENTOS ALEATORIOS.
El conocimiento de la superficie sembrada con cultivos extensivos es de relevancia estratégica para el país y necesita ser estimada en forma objetiva dos veces al año para las principales Provincias Argentinas. El método aquí propuesto es el de observar –con el significado literal de la palabra- una muestra de segmentos que se definen, como relativamente pequeñas áreas que toman la forma de polígonos rectangulares, sin consultar a los dueños de las tierras, a los productores ni a ninguna persona relacionada con las explotaciones que contiene el segmento.
La selección original es de puntos aleatorios dentro de estratos de uso homogéneo del suelo, que luego se los transforma en segmentos. Es obvio que gran parte de los puntos caerán en lugares que no se pueden acceder con un vehículo y para poder llevar a cabo la observación es necesario trasladar el punto hasta el camino más próximo y allí conformar el segmento. Desde el punto de vista de la teoría del muestreo se reconoce que el procedimiento de trasladar origina un sesgo el cual es un error no debido al muestreo.
La contrapartida es que el método tiene importantes ganancias, entre ellas: a) muy alta confiabilidad de los datos por provenir de observaciones “in situ” hechas por expertos, b) no hay error en la medida de las superficies por utilizar tecnología satelital, c) una vez definido el segmento el Sistema de Posicionamiento Global (GPS) permite controlar el operativo y anula el error de ubicación de los segmentos en futuros operativos, d) las muestras son altamente comparables en el tiempo, e) los resultados se obtienen en breve tiempo, en general no más de tres meses, f) reducción notable del presupuesto al no existir revisitas.
El método incorpora nuevas tecnologías, entre ellas: imágenes satelitales, Sistemas de Información Geográfica (GIS), el GPS, el uso del Índice de Vegetación de Diferencia Normalizada (NDVI), programas de procesamiento de la información y protocolos estrictos de procedimientos.
Desempeño de las PyME industriales argentinas, 2005-2011: Medición de eficiencia en la producción a través de un enfoque no-paramétrico.
Este trabajo mide la eficiencia en la producción de las PyME industriales argentinas a partir de la productividad total de los factores, para el período 2005-2011, utilizando datos a nivel empresa, y aplicando el enfoque Análisis Envolvente de Datos (DEA por sus siglas en inglés) basado en el trabajo de Farrell (1957) y las extensiones introducidas por Charnes et al (1978) y Banker et al (1984). Se busca generar un aporte desde el punto de vista metodológico, como antecedente en lo referido a cómo puede medirse la eficiencia de las PyME industriales argentinas en base a información estadística disponible, y explorar cuáles son los factores determinantes de la misma, ya que hasta el momento hay un vacío de información en este sentido. A partir de esto, se explora la asociación de este nivel de eficiencia con factores exógenos a las empresas o internos a las mismas como potenciales determinantes del mismo. Se encuentra que las PyME localizadas en las regiones del país de mayor desarrollo relativo y concentración de la actividad económica tienen un nivel de eficiencia en promedio mayor al resto. Mientras que, sorprendentemente, no hay evidencia suficiente para suponer que el sector de actividad de pertenencia está relacionado con el nivel de eficiencia en la producción. Por otro lado, contrariamente a lo esperado, las empresas más grandes, que exportan, y que solicitan y obtienen créditos bancarios, registran en promedio menores niveles de eficiencia que el resto, aunque esto podría explicarse por el hecho de que estas firmas están más capitalizadas, lo que, al incrementar su dotación del factor de producción capital, impacta negativamente en su eficiencia técnica de producción.
Análisis multivariado aplicado a la generación de escenarios complejos en torno a concepciones de sexualidad y género en alumnos de escuelas medias.
En el presente artículo se exponen aspectos analíticos y metodológicos de la aplicación de diversas técnicas de análisis de datos multivariados empleadas en una investigación sobre salud sexual y reproductiva y educación sexual. Se propone la categoría de escenarios complejos como construcción analítica que permite poner en vinculación concepciones, creencias y actitudes sobre sexualidad, diversidad sexual, género y aborto en base a un relevamiento por encuestas estructuradas en mujeres y varones adolescentes escolarizados en el nivel medio de Argentina realizado durante el segundo semestre del 2012. Dicho relevamiento tuvo como propósito principal indagar y explorar las formas en que determinadas concepciones sobre la sexualidad y el género de los alumnos se vinculan con modelos de educación sexual, las temáticas priorizadas en dichos abordajes, las formas en que se establecen los vínculos con docentes y adultos, los vínculos afectivos intrageneracionales, y las instancias de subjetivación juvenil. Se aplicaron una serie de técnicas estadísticas multivariadas: análisis de componentes principales, análisis de cluster por el método de K-medias y, fundamentalmente, el análisis de correspondencias múltiples para la generación de los escenarios complejos.
Las elecciones a Presidente de Argentina en 2011 y 2015.
La elección a Presidente en Argentina de 2011 tuvo como ganadora a la candidata por el Frente para la Victoria Cristina Kirchner con una amplia diferencia respecto al segundo. El triunfo de la candidata tiene diferentes explicaciones causales desde el punto de vista de las motivaciones del voto por parte del electorado. A través de la presente investigación se intenta identificar las variables condicionantes y jerarquizarlas. Las características socio demográficas del ciudadano no tienen la influencia de otros momentos. En cambio, variables relacionadas con la gestión, el posicionamiento de los candidatos y el vínculo entre Néstor Kirchner y su esposa adquieren mayor protagonismo como condicionantes del voto.
El triunfo de Mauricio Macri en la elección presidencial de 2015 también tiene sus explicaciones causales. Sin entrar en la profundidad de la elección de 2011, se encontraron aspectos ideológicos y vinculados al consumo como elementos motivadores del voto.
Las estadísticas educativas y los desafíos futuros: un sistema de información por alumno.
Este trabajo analiza tanto los antecedentes como las características actuales del sistema de información estadística del sistema educativo argentino. Se plantea también el camino futuro de este sistema, teniendo en cuenta los cambios tecnológicos que tuvieron lugar en nuestro país en los últimos años.
Actualmente, el sistema nacional de información educativa está basado, principalmente, en el Relevamiento Anual, operativo censal que recoge con un corte anual la información consolidada a nivel nacional sobre las principales variables del sistema educativo, exceptuando las universidades. Este sistema garantiza una información homogénea y comparable para todo el ámbito nacional.En la actualidad el sistema de información educativa enfrenta nuevos desafíos producto de un sistema educativo complejo y en constante transformación. Además, el Relevamiento Anual presenta varias limitaciones y solo permite analizar en forma parcial los nudos críticos del sistema educativo. Para paliar estas limitaciones, durante los años 2013 y 2015, se desarrolló un Sistema Integral de Información Digital Educativa —SInIDE—, basado en información nominal de los alumnos. Este nuevo sistema articula y compatibiliza los requerimientos de información de las distintas instancias de gestión en los niveles nacional y jurisdiccional y permite que las instituciones educativas desarrollen a través de este sistema sus propios procesos administrativos y pedagógicos. Su potencialidad radica en la posibilidad de acelerar todos los procesos y de recoger datos adicionales para diagnosticar el funcionamiento del sistema educativo y las trayectorias educativas de los alumnos, tanto a nivel de los establecimientos como a nivel provincial o nacional. Además, permite la construcción de nuevos indicadores para evaluar la situación del sistema educativo en todo el país, fortaleciendo las políticas que se llevan a cabo en el marco de la Ley de Educación Nacional.
El análisis de redes sociales como herramienta para focalizar la intervención en entornos rurales a través de políticas públicas.
Este trabajo muestra los resultados mediante la aplicación de un instrumento de recolección de datos reticulares para un estudio de línea de base y evaluación de políticas públicas en entornos rurales, a fin de describir, medir y comparar las formas de las asociaciones entre los agentes involucrados de dos cooperativas.
Los objetivos de la ponencia radican en describir y caracterizar las redes de asociaciones de pequeños productores rurales en un contexto social delimitado, y evaluar la viabilidad de complementar los análisis estadísticos cuantitativos tradicionales con la metodología del análisis de redes sociocéntricas, para focalizar las formas de intervención y detectar asociaciones latentes y potenciales.
Los resultados obtenidos al aplicar este instrumento en dos agrupaciones de pequeños productores rurales del Noroeste argentino, beneficiarios de un programa social en el año 2014, muestran dos grafos multiplexados diferenciados. Mientras que en la primera red la forma de las asociaciones para movilizar recursos estratégicos se encuentra restringida por la autoridad de los referentes de la organización, en la segunda se observa una distribución más equitativa y menos autoritaria de los vínculos, así como una intermediación menos centralizada.
Se concluye que esta metodología ha sido adecuada para describir las fuerza, dirección y circulación de las relaciones entre los nodos de las agrupaciones relevadas, así como la existencia de asociaciones potenciales que no sean efectivizado. De esta forma la toma de decisiones se ve beneficiada al disponer de información específica, que permite detectar la necesidad de fortalecer vínculos, así como la posibilidad de identificar nodos y subgrupos que centralizan la intermediación y los recursos o que pueden desarrollar una mejor circulación de los mismos a causa de sus posiciones estratégicas en las redes.
Las clases sociales según los censos de población de 1991 y 2001.
El artículo presenta una metodología para la reconstrucción de las series del Nomenclador de Condición Socio-Ocupacional y el esquema de clases de Torrado a lo largo del período 1980-2001, durante el cual los cambios en los sistemas clasificatorios de las variables involucradas en su construcción presentaron importantes cambios. Se utilizaron los datos secundarios del estudio “Estructura Social Argentina” del Consejo Federal de Inversiones para el censo de 1980 y los datos publicados por el Instituto Nacional de Estadística y Censos de los censos de población de 1991 y 2001, para el Total del País.
La investigación aborda tanto las cuestiones metodológicas enfrentadas a la realidad de la oferta estadística en Argentina así como también aspectos teóricos sobre la temática de la estructura social. Se realiza un detallado análisis de las fuentes existentes que permiten la construcción de series lo más homogéneas posibles en términos metodológicos con el objetivo de que muestren los cambios de la estructura social entre fines de los cuarenta y la actualidad. Se analizan también los resultados alcanzados. En lo que hace a este aspecto, sin embargo, la profundidad de la indagación es menor.
El aporte permite continuar y armonizar, con las dificultades y advertencias metodológicas que implica, los trabajos de Germani (1955) y Torrado (1992) y el análisis de la estructura social Argentina según datos secundarios cuantitativos.
Palabras clave: Condición Socio-Ocupacional; clases sociales; censos de población; estructura social argentina; mercado de trabajo; ocupación; empleo.
RAESTA 2 - año 2 (2015)
Artículos
Metodología estadística para la estimación de las superficies sembradas con cultivos extensivos - método de segmentos aleatorios.
Norberto V. Rodríguez / Julieta Mirensky

1. Introducción
El presente trabajo corresponde a la metodología del diseño de una muestra con el objetivo básico de estimar las superficies sembradas con cultivos de tipo extensivos en las principales provincias, regiones y jurisdicciones del país, que ha comenzado a aplicarse en el ámbito del Ministerio de Agricultura Ganadería y Pesca (MAGyP) desde la campaña agrícola de los años 2011/2012.
En relación al tamaño de los granos del cultivo y de la época en que se siembra, en el país se distinguen dos tipos de campañas agrícolas denominadas:
• Fina: corresponde a los cultivos extensivos invernales sembrados en Mayo/Julio y cosechados en Noviembre/Enero, como trigo, cebada, centeno, avena y colza.
• Gruesa: cultivos extensivos que comienzan a sembrarse en Septiembre y se cosechan hacia Enero, los principales son soja, maíz, sorgo y girasol.
Es de fundamental importancia para la planificación en el sector agrícola disponer de estimaciones anuales de las áreas sembradas con los cultivos para ambas campañas.
Históricamente, la información estadística del MAGyP se basó en un Método Subjetivo que parte de informantes calificados con la incorporación de controles y validaciones con datos provenientes de fuentes comerciales y productivas (acopiadores, cooperativas, productores, distribuidores de agroquímicos y semillas, etc.).
Los informantes calificados proveen gran variedad de datos necesarios, pero en lo que se refiere a la estimación de las hectáreas cultivadas tienden a producir desfasajes acumulativos en el tiempo y la no captación suficientemente rápida de los cambios regionales. Esto motiva la necesidad de disponer de información objetiva, es decir que no esté fundamentada en opiniones personales.
En consecuencia se desarrolló el método que se presenta en su faceta estadística, que se denominó de Segmentos Aleatorios, basado en un muestreo probabilístico de áreas, para la estimación de las superficies sembradas con cultivos extensivos en diferentes zonas agrícolas del país.
2. Incorporaciones tecnológicas
2.1. Antecedente de las encuestas por muestreo en el sector
Hasta hace unos 15 años se realizaban encuestas agropecuarias basadas en entrevistas directas (face to face) a productores, esta metodología tuvo que ser dejada de lado debido a una creciente tasa de no respuesta debido a motivos, tales como:
a. Aumento del número de productores no residentes en la explotación, que se los debe buscar en domicilios ubicados en alguna localidad no siempre cercana, lo cual requiere de encuestadores con dotes de detective.
b. Surgimiento del método de producción “Pool de siembra”, caracterizado por un sistema empresarial transitorio que asume el control de la producción agropecuaria mediante el arrendamiento de grandes extensiones de tierra, el uso de equipos propios o contratados para siembra, fumigación, cosecha y transporte. En general son difíciles de localizar y usualmente se niegan a suministrar información.
c. Aparición de robos e inseguridad, que produce el efecto de tranquera cerrada y para ingresar a la explotación se necesita gestionar un permiso previo.
d. En el caso que el encuestador logre contactar al productor, es frecuente la negación a responder el cuestionario o que se brinden respuestas incorrectas (generalmente asociado a conflictos impositivos).
La consecuencia de los problemas citados era un alto costo operativo para muy escasa respuesta confiable, incremento de las visitas a un mismo productor y demoras en la recolección y procesamiento de los datos.
En el mediano plazo no se espera el mejoramiento de las condiciones ya señaladas, por ello se necesita un diseño de muestra y un operativo de campo que no dependa de “entrevistas a productores”.
2.2. Incorporaciones tecnológicas del método
El nuevo método de segmentos aleatorios contempla el uso de nuevas tecnologías:
• Datos básicos obtenidos mediante la observación directa de la cobertura del suelo de cada lote, sin consultar a los productores ni a los dueños de las tierras.
• Uso de imágenes de alta y mediana resolución originadas por los satélites Landsat y Spot, el sensor Modis ubicado en los satélites Terra y Aqua y el programa Google Earth.
• Sistemas de posicionamiento global (GPS), para determinar coordenadas que permiten ubicar puntos de referencias sobre la superficie terrestre y sobre las imágenes satelitales.
• Software de información geográfica (ArgGIS, Quantum GIS).
• Programas “SPSS Statistical” y “Minitab” para el procesamiento, análisis y obtención de resultados.
• Estrictos protocolos de trabajo para organizar la información y elaborar bases de datos.
3. Objetivos y condicionamientos
3.1. Objetivo general del método
• Estimar las superficies sembradas con cultivos de tipo extensivos especificados, a nivel de Partidos -en la Provincia de Buenos Aires- y Departamentos -en las restantes provincias-. Estos constituyen el nivel máximo de desagregación, la adición de niveles conducen a regiones o incluso a provincias completas.
3.2. Objetivos específicos
• Obtener estimaciones anuales que sirvan como base de ajuste de múltiples estimaciones subjetivas.
• Generar un Sistema de Información Geográfica (SIG) que permita:
• El soporte de los sucesivos operativos a campo
• La fuente de consulta para problemas de gestión y planificación
• La generación de Información Agrícola en forma de series temporales
• Establecer un proceso de mejora continua de la metodología, incluyendo el aumento progresivo de la superficie en estudio con la incorporación de nuevos Partidos y Departamentos del país.
3.3. Condicionamientos del diseño
El diseño de la muestra tuvo que superar varias condiciones restrictivas; se citan:
a. Suministrar estimaciones para los niveles de Partidos/Departamentos en los que se desarrolla actividad agrícola extensiva (se excluye La Patagonia y zonas cordilleranas). Estos son un número importante y se necesita una muestra de gran tamaño.
b.Información básica obtenida mediante visualización directa de la cobertura del suelo por parte de un observador, con el soporte de imágenes satelitales. Este procedimiento implica la pérdida de datos que no son observables, como intención futura de siembra, régimen de tenencia, etc.
c. Estimar los errores debidos al muestreo, a efectos de verificar que las superficies con los principales cultivos se ubiquen dentro de niveles aceptables. Por tanto, se precisa una muestra probabilística.
d. Estratificar dentro de cada Partido/Departamento creando zonas de uso homogéneo del suelo, con el objetivo de disminuir el error debido al muestreo. La estratificación en el sector agrícola es una tarea compleja que requiere utilizar tecnología satelital.
e. Definir áreas relativamente pequeñas de superficie terrestre, que son las unidades de observación que se les adjudicó la denominación de segmentos. Seleccionar sobre imágenes y mapas no presenta dificultad, pero al observador en campo le resultará difícil sino imposible acceder a dichas áreas en caso de que se ubiquen en lugares sin caminos públicos.
f. Relevar el 100% de cada segmento, pueden contener además de los cultivos extensivos, otros cultivos (producción hortícola, frutícola, etc.) y desperdicio agrícola (urbanizaciones, montes, caminos, inundaciones transitorias, etc.).
g. Reducir el tiempo destinado a trabajo de campo y procesamiento de datos, idealmente a no más de tres meses.
h. Repetir dos veces por año el operativo -coincidente con las campañas agrícolas- dentro de un presupuesto restringido a los recursos del MAGyP (personal, equipamiento informático y vehículos disponibles).
Nótese que la condición 1 actúa en sentido opuesto a las condiciones 7 y 8.
La condición 2 conduce a tener que aceptar un sesgo estadístico, ya que para poder efectivizar las observaciones de los segmentos, se requiere alterar la aleatoriedad de la selección originalmente asignada.
4. Proceso Estadístico de elaboración del diseño de la muestra
4.1. Esquema del diseño de la muestra
Desde el punto de vista de la teoría del muestreo, se trata de un diseño de muestra probabilístico de áreas, en una sola etapa, con estratificación de las unidades de muestreo de acuerdo al uso de la tierra y selección simple al azar de estas unidades dentro de cada estrato.
En esta aplicación la unidad de muestreo es el segmento, que una vez definido pasa a integrar un sistema de visitas periódicas repetitivas en el tiempo, para ser observados de acuerdo a las necesidades de información, es decir que se le adjudica el carácter de permanente.
El procedimiento en cuanto al diseño de muestra requirió cumplir la siguiente serie de pasos.
4.2. Eliminación de superficies con probabilidad nula de ser cultivadas
La tarea inicial consistió en excluir aquellas superficies con probabilidad nula (actual o futura) de producción agrícola. Se lleva a cabo por Partido/Departamento Provincial, mediante un análisis de imágenes satelitales Lansat y del programa Google Earth, también se tuvo en cuenta el conocimiento de los delegados del MAGyP. Las áreas excluidas corresponden a:
• Ciudades y poblaciones
• Cuerpos de agua permanente (lagunas y ríos) y bajos inundables
• Sierras y pendientes pronunciadas
• Franjas de playas, dunas, bosques
Estas superficies configuran el Descarte, obviamente no revisten de interés para el operativo y solo importan a efectos de su exclusión del marco de selección.
4.3. Estratificación
Se define como Estrato a aquellas zonas dentro de cada Partido/Departamento que se caracterizan por un uso agrícola homogéneo del suelo. Los estratos presentan formas irregulares y no tiene porqué formar superficies continuas ni seguir límites de jurisdicciones; pueden cortar las explotaciones agropecuarias con líneas precisadas sobre las imágenes, aunque no observables sobre la superficie.
El objetivo fundamental de la estratificación es aumentar la precisión de las estimaciones que se obtengan por la muestra (estimaciones con menor error debido al muestreo), pero no reviste ningún interés suministrar información a nivel de estrato.
La estratificación es una tarea realizada por especialistas en la interpretación de imágenes, en este caso provenientes de los satélites Landsat y Spot y del sensor MODIS (Espectroradiómetro de Imágenes de Resolución Moderada) ubicado en los satélites Terra -orbita en dirección Norte-Sur cruzando el Ecuador por la mañana- y Aqua –orbita de Sur a Norte cruzando el Ecuador por la tarde- y además se utiliza el programa Google Earth para determinar y medir estas zonas.
Desde un punto de vista general se diferencian 4 estratos básicos:
• Estrato A: Zonas con un alto porcentaje de aptitud agrícola
• Estrato B: Zonas mixtas con un mayor porcentaje de aptitud ganadera
• Estrato C: Zonas sólo aptas para uso ganadero
• Estrato D: Tierras con probabilidad nula de utilización agrícola o pecuaria.
No obstante, en algunas provincias y zonas, de acuerdo a las necesidades de estimación propias de cada una, se pueden adicionar otros estratos de interés.
La estratificación se actualiza continuamente, ya que el uso de la tierra es susceptible a modificaciones en el tiempo.
4.4. Procedimiento para estratificar
Entre 2010 y 2012 la estratificación se realizó en forma visual por expertos en interpretación de imágenes del Landsat; éste es un método subjetivo, ya que distintas personas pueden conformar los estratos de forma diferente. Por otra parte toda imagen se relaciona con una fecha y un cambio de la fecha puede modificar los resultados.
Advertido de esto en el año 2012 se incorporó el uso del Índice de Vegetación de Diferencia Normalizada (NDVI, por sus siglas en inglés), el cual permite estimar el estado de desarrollo de la vegetación a partir de datos espectrales proporcionados por el sensor MODIS. Terra-MODIS y Aqua-MODIS que cubren la superficie de la Tierra en aproximadamente dos días, adquiriendo datos en 36 bandas espectrales de las cuales las Bandas 1 y 2 son las que interesan para la medición de coberturas vegetales.
El Índice aprovecha el particular comportamiento radiométrico de la vegetación sana en las diferentes bandas espectrales, especialmente el visible y el infrarrojo cercano. En el visible se dispone de la banda 1 correspondiente al rojo, donde los pigmentos de la hoja absorben la mayor parte de la energía que reciben del sol y en consecuencia la reflectancia es baja. La banda 2 está ubicada en el infrarrojo cercano y el comportamiento es inverso al anterior, ya que es escasa la energía que absorben los pigmentos de la hoja y la reflectancia es alta.
El siguiente gráfico presenta la ubicación de las 7 primeras bandas del censor MODIS, identificadas desde la B1, hasta la B7 en relación de la longitud de onda. Se marcó con un círculo verde el comportamiento normal de la vegetación sana en las bandas 1 y 2, que son las que particularmente interesan.
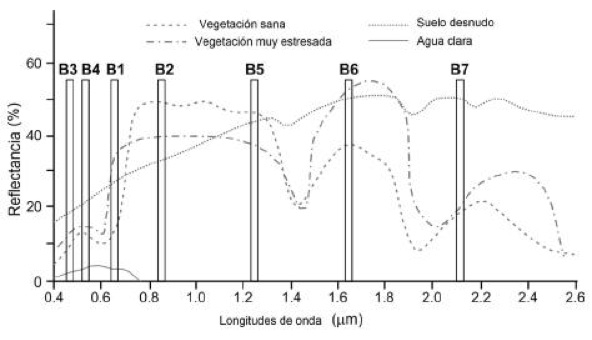
La banda 1 (rojo) mide la reflectancia en la longitud de onda entre 0,620 μm a 0,670 μm y la banda 2 (infrarojo) en la longitud de onda entre 0,841 μm a 0,876 μm. En el gráfico se observa que la vegetación sana tiene un porcentaje de reflectancia mayor en la banda 2 que en la banda 1. Este contraste es usado para calcular el NDVI para cada pixel, el cual se define como el cociente:
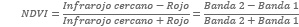
El NDVI expresa la relación entre la energía absorbida y emitida, útil para medir la cantidad, salud y vigor de la vegetación. Las variables banda 2 y banda 1 se definen por las medidas de reflexión espectral que adquieren en esas regiones del espectro electromagnético. El índice toma valores en el intervalo [-1, +1], lo que lo convierte en un indicador sumamente útil.
El procedimiento que determina el estado de la vegetación en un pixel consiste en tomar el valor más alto del NDVI durante periodos consecutivos de 16 días. Esto genera una serie de puntos con los cuales se construye una curva multimodal, variable según el tipo de cobertura. En el siguiente ejemplo se presenta la curva generada por un mismo pixel a través de dos años, en los cuales en su superficie se sembró primero trigo, luego soja y finalmente maíz.
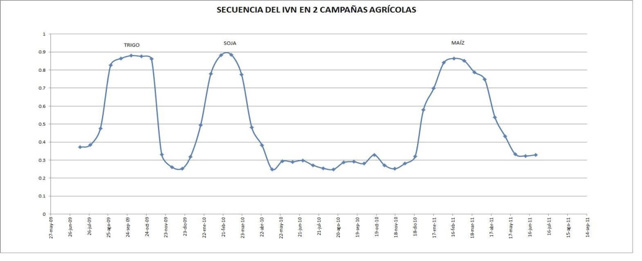
El pixel del ejemplo sería clasificado como “pixel agrícola”. En caso de que se presente una línea más regular cercana y paralela a la ordenada sería un “pixel agrícola”.
El paso siguiente es la delimitación de los estratos: en la imagen satelital se superpone una grilla hexagonal de 2.500 hectáreas de superficie, donde cada hexágono estará compuesto por una cantidad de pixeles -agrícolas y no agrícolas-.
Se calcula para cada hexágono la proporción de pixeles destinados a la actividad agrícola. Si el porcentaje de píxeles agrícolas del hexágono es:
• P% > 70% → es un hexágono agrícola: A= Agrícola
• 30% ≤ P% ≤ 70% → es un hexágono mixto: B= Mixto
• P% < 30% → es un hexágono ganadero: C= Ganadero
Se agrupan todos los hexágonos de un mismo tipo, y por interpretación de las imágenes resultantes se forman dentro de cada Partido/Departamento, los estratos de uso internamente homogéneo del suelo.
4.5. El segmento como unidad de muestreo
Se mencionó que la Unidad de Muestreo del diseño es el Segmento que se define dentro de cada estrato como una superficie con forma de polígono, generalmente rectangular, generada a partir de una ruta o camino identificable, de 4 Km de largo y 500 metros a cada lado. Por tanto, el área total de cada segmento se aproxima a las 400 hectáreas.
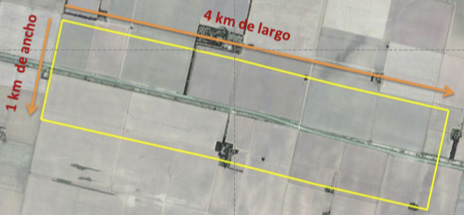
Se realiza un esfuerzo para lograr segmentos de igual tamaño a los efectos de cumplir dos objetivos: 1) evitar tener que incorporar la “superficie del segmento” como una variable en un estimador y 2) facilitar la comparabilidad entre segmentos.
En la mayoría de las provincias se logró tener segmentos iguales, las excepciones fueron algunos Departamentos con alto nivel de Descarte que hicieron necesario definir segmentos de tamaño variable; en estos casos se trabaja con estimadores por razón a la superficie del segmento en lugar de simple expansión.
En cada segmento elegido:
• Se observa en forma directa el 100% de su superficie. Consecuentemente, salvo errores de interpretación, el segmento constituye la verdad terrestre o verdad de campo.
• Se identifican las Unidades de Uso de Suelo (UUS) que son las diferentes coberturas que contiene, sean o no agrícolas.
4.6. Tamaño de la muestra, por Partido/Departamento
El método para estimar las superficies sembradas parte de seleccionar una muestra aleatoria de puntos. Como se necesita suministrar estimaciones para cada Partido/Departamento, la cantidad de puntos -futuros segmentos- se determinan independientemente para cada estrato de estas jurisdicciones.
El tamaño de la muestra es una aproximación que se realiza teniendo en cuenta los criterios estadísticos conjuntamente con el conocimiento de: a) el tipo de Estrato, b) la superficie del Estrato, c) información previamente disponible de la zona y d) comportamiento de los parámetros de los principales cultivos.
El principal procedimiento de estimación del tamaño de muestra utiliza un modelo de regresión logarítmica donde la variable explicativa es la superficie del estrato y la explicada la cantidad de segmentos. Es decir:
nh = A + B x log10 (Superficie Estrato h)
Donde: nh: tamaño de la muestra del h-ésimo estrato
Otra alternativa también utilizada para estimar el tamaño de la muestra es partir de un Coeficiente de Variación prefijado y estimaciones del error relativo, según la expresión:
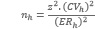
Donde
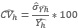 Coeficiente de variación
Coeficiente de variación
z = valor de la variable de una distribución normal estandardizada de probabilidad
Error Relativo
La suma de puntos elegidos dentro de cada estrato de un Partido/Departamento es el tamaño de la muestra de esta jurisdicción y por agregación del total provincial.
4.7. Selección de los Segmentos
Se seleccionan puntos aleatorios sobre la superficie de cada combinación Estrato y Partido/Departamento, con excepción de la zona de Descarte. Es decir que la unidad estadística original es un punto sobre la superficie terrestre. Hasta aquí el diseño de muestra es estrictamente aleatorio.
El inconveniente de este procedimiento es que los puntos caen en cualquier parte de la superficie, frecuentemente dentro de explotaciones y lotes no alcanzables a través de un camino. Esta situación hace necesario reubicarlos a la posición accesible más cercana, evitando producir sesgos significativos por pérdida de aleatoriedad. La solución consiste en trasladar el punto hasta el camino más cercano, tal que pueda arribarse con un vehículo y sin necesidad de contar con la autorización previa del propietario, productor u ocupante de las tierras.
En la práctica se utiliza un Sistema de Información Geográfico (GIS) y se superpone la capa de imágenes satelitales con la de caminos y a partir del punto se crea una circunferencia a la que se incrementa progresivamente el radio, hasta producir el primer contacto con un camino identificable. La intercepción “Circunferencia-Camino” define el punto elegido.
Dado que no es posible estimar áreas en base a puntos, se procede a transformar el punto en una superficie siguiendo los siguientes pasos:
1. Creación de un segmento lineal a partir del punto elegido sobre el camino: para ello se establecen dos nuevos puntos opuestos y equidistantes, a dos kilómetros del mismo. Se unen para dar origen al segmento lineal de 4 kilómetros de largo.
2. Transformación del segmento lineal en un polígono mediante el trazado de dos líneas paralelas a 500 metros a cada lado del camino.
Surge así una superficie de forma rectangular -excepto por la aparición de alguna curva o algún descarte- de 4 Km de largo por 1 Km de ancho, que salvo pequeños ajustes comprende un área de 400 Ha.
Se considera que desde un camino una distancia 500 metros usualmente es visible para el observador, no obstante deberá encontrar la forma de acercarse a los lotes más alejados.
Una consecuencia del mecanismo de traslado es que dos segmentos podrían solaparse en un mismo camino. En casos como el descripto se separan dejando 2 km. libres entre la finalización de uno de y el comienzo del otro.
Otra ocurrencia asociada al proceso es la necesidad de alterar la forma rectangular de los segmentos ante la presencia de descarte (manteniendo las 400 Ha.). Ejemplo de ello son

Cada segmento cumple con los siguientes requisitos:
a. Pertenece en su totalidad a un mismo Estrato de un Partido/ Departamento.
b. Posee un tamaño de 400 hectáreas, con una tolerancia de hasta ± 5% (entre 380 y 420 hectáreas). No obstante se tuvieron en cuenta excepciones a esta regla en algunos Departamentos que presentaron estratificaciones complejas.
c. Ostenta el carácter permanente: Como no existe sesgo por cansancio de la unidad de respuesta ya que no se entrevistan personas, una vez delimitado cada segmento en la cartografía digital no será modificado en los sucesivos operativos, excepto alguna circunstancia que lo justifique. De esta forma la información de cada segmento es una serie de tiempo, de comparabilidad directa.
d. Se identifican mediante un código de 9 dígitos que define:
• Provincia = primeros dos dígitos
• Partido o Departamento = siguientes tres dígitos
• Estrato = letra A, B o C
• Orden = últimos tres dígitos
De esta manera no hay posibilidad de que existan dos segmentos con igual numeración. El código facilita la determinación, comparación y la repetición de operativos semejantes en el tiempo.
Previo a la asignación del carácter “permanente” de los segmentos, personal técnico del Ministerio realiza una salida a campo para evaluar “in situ” la factibilidad de acceso y el recorrido de los segmentos. Si surgen anomalías, por ej., caminos cerrados, se informa a Sede Central para que evalúe la situación y actúe en consecuencia.
4.8. El sesgo debido al traslado
Trasladar el punto de su ubicación aleatoria original hasta el camino más cercano se presenta como la única posibilidad de lograr la verdad de campo, ya que la alternativa de consultar el productor no es factible y tampoco lo es estimar a partir de clasificaciones supervisadas o no supervisadas de imágenes satelitales -en Argentina la observación del uso del suelo en las imágenes presenta un alto grado de confusión y los resultados no son aceptables-.
La duda que se plantea es si el corrimiento genera un sesgo que pueda ser significativo. Con el objetivo de tener una respuesta sobre este Interrogante se implementaron varias pruebas, la principal fue una investigación llevada a cabo en el Partido 25 de Mayo de la Provincia de Buenos Aires que consistió en delimitar pares de segmentos, uno sobre el punto original (segmento original), y el otro sobre el punto trasladado (segmento trasladado).
Mediante acuerdos con asociaciones de productores se logró a modo de excepción los permisos para entrar al interior de los campos y observar el contenido de los lotes de los segmentos originales.
Se llevaron a cabo dos estimaciones por separado, una utilizando el conjunto de segmentos trasladados y otra con el conjunto de segmentos originales.
Los resultados fueron dos estimaciones independientes para cada cultivo del Partido de 25 de Mayo, las que no presentaron diferencias considerables en los cultivos importantes, aunque sí en los cultivos menos extensivos y localizados que no son de interés para el presente estudio. Es decir que como una primera conclusión se considera que en las Provincias de la Región Pampeana el efecto traslado no es significativo en cultivos extensivos, especialmente porque hay suficientes caminos y los traslados son distancias cortas realizadas siempre dentro de un mismo estrato. En provincias extrapampeanas no se han llevado a cabo este tipo de estudios.
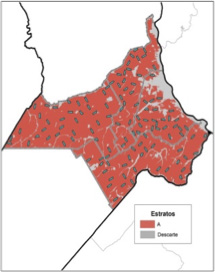
4.9. Ejemplo de segmentos ubicados en la Delegación Casilda
El siguiente mapa muestra a los segmentos ubicados en la Delegación Casilda de la Provincia de Santa Fe, la cual comprende los departamentos de: Caseros, Constitución, Rosario y San Lorenzo.
Esta región de la Provincia de Santa Fe y abarca 1.058.626 Ha. Es una zona que se caracteriza por un uso de suelo muy homogéneo, por tanto sólo fue definido un solo estrato agrícola de 934.803 Ha., más un descarte de 123.823 Ha. Se puede observar que se ubicaron en total 114 segmentos.
5. Unidades del Uso del Suelo
Las Unidades de Uso del Suelo (UUS) son las diferentes coberturas que se le presentan al observador a medida que recorre cada uno de los segmentos, pueden ser agropecuarias o no agropecuarias y constituyen la verdad de campo.
Cada segmento se integra de una cantidad variable de UUS.
Se supone el siguiente ejemplo de un segmento compuesto con solo cuatro tipos de UUS:
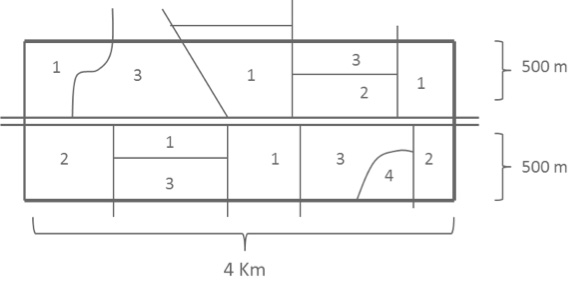
1 = Trigo
2 = Cebada Cervecera
3 = Avena
4= Caserío
De los datos del cultivo y la superficie de cada lote, surge el siguiente cuadro:
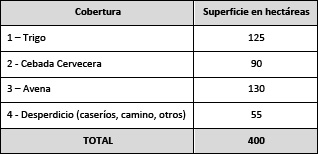
No obstante que los usos no agrícolas identificables son previamente descartados del marco, dentro de cada segmento siempre aparecen diferentes tipos de Desperdicios, frecuentemente transitorios que no fueron eliminados, tales como: rutas y caminos, viviendas rurales, parques, arboledas, vías férreas, canales, aeródromos, cementerios, instalaciones deportivas, esteros, médanos, floraciones rocosas, pendientes pronunciadas, cañadas, anegamientos temporales, etc. Este conjunto no reviste interés, no obstante se lo estima a partir de una variable que se define como la diferencia entre la superficie total del segmento y la superficie agrícola relevada.
Las variables del estudio que interesan son los usos agropecuarios del suelo. En total se consideran 33 usos:
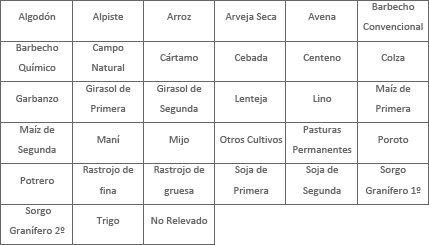
La variable superficie “No Relevada” corresponde a toda UUS que pese a haber sido delimitada en el segmento, por imposibilidad de acceso o incluso por omisión, no se le identificó la cobertura. En la práctica no reviste significación.
6. El Operativo a Campo
6.1. Tareas de los Delegados
La obtención de la información básica de cada segmento es responsabilidad de los Delegados del MAGyP con asiento en el interior del país, estos cumplen el rol de observador. A cada Delegado se le suministra el material necesario para cumplir adecuadamente su tarea:
1. Archivos SIG por Partidos/Departamento, de Segmentos, de UUS, de cartografía base, de rutas y de ubicación de principales ciudades y pueblos.
2. Imágenes satelitales del Lansat 8.
3. Archivos GPS con las coordenadas de inicio y fin de cada segmento.
4. Planillas de campo varias, útiles en el relevamiento.
El observador con el GPS marca los waypoints de todas las UUS que va encontrando, a ambos lados de la línea de recorrido del segmento, como también las UUS ubicadas lejos de la línea de recorrido pero que están dentro del segmento.
Terminadas estas tareas, remite la información mediante FTP (Protocolo de transferencia de archivos) a la Oficina Central de Estimaciones.
6.2. Tareas en la Oficina Central de Estimaciones
Una vez recibida la información, se realiza un análisis de consistencia y coherencia, y si aparecen dudas al comparar lo relevado con lo visualizado en la imagen satelital se consulta con el Delegado responsable.
Se procesa la información y se elaboran las Planillas Resumen de la Muestra, de la cual surge para cada Partido/Departamento el cruzamiento de los segmentos como filas y las diferentes coberturas como columnas. A partir de las mismas, se ejecuta el proceso de expansión y por el programa SPSS se obtienen las estimaciones de las superficies de cada tipo de cobertura.
Se consideran dos tipos de estimadores con sus respectivas variancias:
• Estimadores por simple expansión, para Partidos/Departamentos donde los segmentos son de igual tamaño (400 Ha).
• Estimadores por razón separada, para Partidos/Departamentos donde los segmentos son de diferente tamaño.
7. Generación de los estimadores
7.1. Definiciones básicas de la teoría del muestreo
El objetivo primario de toda investigación por muestreo es estimar parámetros -valores cuantitativos desconocidos- de una población en estudio. Para ello se utiliza el procedimiento de encuestar u “observar” a una muestra de las unidades que conforman la población. Si la selección se realiza por algún procedimiento aleatorio aceptado por la teoría del muestreo, la muestra es probabilística.
En el presente estudio los parámetros corresponden a las superficies en hectáreas de cada una de las diferentes coberturas del suelo en cada Partido/Departamento y en una campaña especificada.
Por su parte los estimadores se definen como las expresiones matemáticas construidas a partir de los datos de la muestra. Como su nombre lo indica tienen como objetivo la estimación de los parámetros.
Toda estimación originada por el método del muestreo tiene dos tipos de errores, los no debidos al proceso de muestreo y los debidos al hecho de observar parcialmente la población.
• Los no debidos al muestreo, son difíciles de medir y en consecuencia rara vez se los llega a conocer; en general dependen de la forma de captación de los datos, luego se pueden reducir con un buen análisis de consistencia y coherencia de la información básica. En la presente investigación es de suponer que este tipo de error no es significativo debido a que los datos se obtienen por observación directa por personal experto y conocedor del sector, con estrictos protocolos, control por GPS y con áreas consistidos y medidas con imágenes satelitales. No obstante en la selección aparece un corrimiento del segmento original hacia caminos y es causa de un surgimiento de error no debido al muestreo.
• Los debidos al proceso de muestreo que no se pueden anular, pero en el caso de una muestra probabilística se los puede medir. Los dos principales indicadores son el Error Estándar (E.Std) y el Coeficiente de Variación (CV).
Ambas medidas están afectadas por el tamaño de la muestra y en consecuencia, salvo excepción, serán mayores a nivel de Partido/Departamento que a nivel de una región. Estos indicadores de la variabilidad cumplen con la condición general de “cuando más pequeño es mejor”.
• El Error Estándar es una medida de la variabilidad dada en cifras absolutas, en la presente investigación expresa el grado de precisión con que la estimación de cada cultivo se aproxima a la verdadera cantidad de hectáreas sembradas.
• El Coeficiente de Variación es una cifra relativa expresada en porcentaje. Esta dada por el cociente entre las estimaciones del error estándar y la superficie estimada de cada cobertura.
CV = Error Estándar de la estimación de la superficie de una cobertura
Estimación de la superficie de una cobertura x 100
El CV asocia la confiabilidad que necesita la investigación con cada parámetro. En la presente se utiliza la siguiente regla:
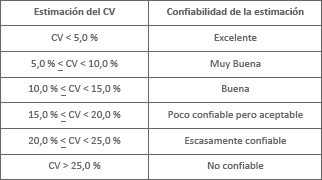
Cuando el CV supera el 25%, se interpreta que las superficies sembradas presentan mucha variabilidad y la estimación debe ser tomada cuidadosamente.
7.2. Estimadores por simple expansión de cada tipo de cobertura
7.2.1. Cantidad de hectáreas con una cobertura determinada en un segmento de un estrato
Dentro de un determinado segmento cada una de las diferentes coberturas de la simboliza se la simboliza.
Sup.Esthi
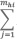 yhi (1)
yhi (1)Dónde
yhij: Cantidad de hectáreas con una determinada cobertura que posee el j-ésimo lote, del i-ésimo segmento, del estrato h de un Partido/Departamento.
mhi: Total de lotes con una determinada cobertura que posee el i-ésimo segmento, del estrato h de un Partido/Departamento.
Sup.Medhi: Cantidad de hectáreas medidas (reales) que posee el i-ésimo segmento del estrato h, de un Partido/Departamento.
yhi: Cantidad de hectáreas con una determinada cobertura que posee el i-ésimo segmento, del estrato h, de un Partido/Departamento.
La superficie de los segmentos tienen una variación tolerable en hectáreas de:
380 Ha. ≤ Sup.Medhi. ≤ 420 Ha.
Por tal motivo, la formula (1) adiciona el factor de ajuste proporcional dado por:
Fhi = 400
Sup.Esthi
Fhi: Salvo excepciones arroja un valor muy cercano a la unidad, al multiplicar cada cobertura del segmento y hace que estas se refieran a una superficie de exactamente 400 Ha.
La población de segmentos que contiene cada estrato, se calcula como el cociente entre la superficie total del estrato sobre 400 hectáreas.
Nh = Sup.Esth
400
Dónde: Sup.Esth: Cantidad de hectáreas que posee el estrato h.
7.2.2. Estimador por simple expansión del total de hectáreas de una cobertura en un estrato h.
Está dado por:
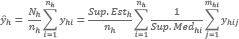 (2)
(2)Dónde:
ŷh: Estimador por simple expansión del total de hectáreas de una determinada cobertura sembrada en el estrato h
nh: Cantidad de segmentos seleccionados que integran la muestra del estrato h
7.2.3. Estimador por simple expansión del total de hectáreas de una cobertura de un Partido/Departamento
Se obtiene como una suma de los estratos especificados en el Partido/Departamento
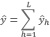 (3)
(3)El mismo estimador expresado según la simbología dada por Horvitz y Thompson.
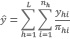 (4)
(4)Dónde πhi es la Probabilidad de que el i-ésimo segmento de la población del estrato h, integre la muestra en una selección simple al azar de “nh” unidades sin reemplazo de la población Nh.
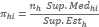
En el procesamiento se considera whi= 1/πhi como el factor de expansión.
7.2.4. Estimadores por Simple Expansión del Error Estándar y el Coeficiente de variación del Total de Hectáreas de una cobertura de un Partido/Departamento
El estimador por simple expansión de la variancia del estimador de un total de una cobertura para un Partido/Departamento, viene dada
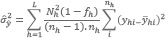 (5)
(5)El error estándar del estimador de un total de una cobertura para un Partido/Departamento
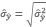 (6)
(6)Y el estimador del coeficiente de variación de un total de una cobertura para un Partido/Departamento
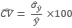 (7)
(7)7.3. Estimadores por razón de cada tipo de cobertura
7.3.1. Estimadores por razón del total de hectáreas con una cobertura en un Estrato
Cuando los segmentos seleccionados presentan variaciones en su superficie, el tamaño del segmento se convierte en una variable aleatoria que usualmente esta correlacionada positivamente con cada tipo de cobertura.
El estimador por razón utiliza ambas variables, la superficie en hectáreas de la cobertura en particular y la superficie en hectáreas del segmento. Toma la forma.
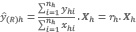 (8)
(8)Donde:
ŷ (R)h: Estimador por razón separada del estrato h
yhi: Cantidad de hectáreas con una determinada cobertura en el i-ésimo segmento seleccionado del estrato h
xhi: Cantidad de hectáreas del i-ésimo segmento seleccionado del estrato h
rh: Razón entre la superficie de una determinada cobertura y la cantidad de hectáreas del total de segmento seleccionados en la muestra en el estrato h.
Xh: Superficie total de hectáreas del estrato h. Este es un parámetro poblacional previamente conocido ya que corresponde a la superficie satelital medida del estrato.
7.3.2. Estimadores por razón del total de hectáreas de una cobertura en un Partido o Departamento.
Es la suma a través de los estratos
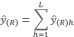 (9)
(9)Donde:
ŷ (R): Estimador por razón separada para un Departamento/Partido
7.3.3. Estimador por razón separada del error estándar y del coeficiente de variación del total de una cobertura en un Partido o Departamento
El estimador de la variancia del estimador de razón es:
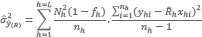 (10)
(10)El estimador del error estándar de razón
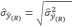 (11)
(11)El estimador del coeficiente de variación
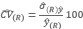 (12)
(12)8. Estimadores por intervalos de confianza
Las fórmulas anteriores corresponden a estimadores puntuales, en el estudio también se elaboran para cada Partido/Departamento estimadores por intervalos e confianza de las diferentes coberturas. Los que responden a la expresión general:
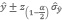 (13)
(13)Donde
ŷ: Estimador puntual de una cobertura (por simple expansión o por razón) para un Partido/Departamento
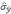 : Estimador puntual del error estándar de una cobertura (por simple expansión o razón) para un Partido/Departamento.
: Estimador puntual del error estándar de una cobertura (por simple expansión o razón) para un Partido/Departamento.
z: Valor de la variable de la distribución normal estandardizada correspondiente a una confianza en probabilidad de “1-α = 0,90”. En este caso en particular z(0,95)= 1,645.
9. Presentación de la información
Como resultado de la muestra se presentan cuadros para cada Partido/Departamento con las diferentes coberturas en las campañas de cosecha fina y de cosecha gruesa, con las siguientes estimaciones sobre la superficie en hectáreas sembradas y otras coberturas,
• Estimación de la superficie sembrada de cada cobertura considerada a nivel de Partido o Departamento.
• Estimación de los errores debidos al muestreo de los estimadores considerados en el punto anterior
• Estimación del coeficiente de variación porcentual de cada cobertura considerada a nivel de Partido o Departamento.
• Estimación por niveles de confianza del 90%. Estos son elaborados a nivel de Partido y de departamento utilizando la distribución de probabilidad “t” de Student o la distribución Normal.
Bibliografía
Ministerio de Agricultura Ganadería Pesca de la República Argentina, Dirección de Información Agropecuaria y Forestal – Año 2013 - Método de segmentos aleatorios, Metodología para la estimación de la superficie sembrada con cultivos extensivos – Versiones 2 y 3 -
FAO Organización de las Naciones Unidas para la Agricultura y la Alimentación – Encuestas Agrícolas con múltiples marcos de muestreo – Año 1996 - Volumen 1.
Cochran, Willams .G. – Año 1963 - Sampling Tecniques – 3 ed. – Wiley.
Tzitziki Janik García-Mora, Jean-François Mas - Evaluación de imágenes del Censor Modis - Vol. 63, N° 1 – Año 2011 - Boletín de la Sociedad Geológica Mexicana.
Scheaffer, Mendenhall, Ott – Año 1987 - Elementos de muestreo – Grupo Editorial Iberoamérica.
RAESTA 3 - Año 3 (2016)
Presentación
Artículos
Desempeño de las PyME industriales argentinas, 2005-2011: Medición de eficiencia en la producción a través de un enfoque no-paramétrico. +Laura MastroscelloAnálisis multivariado aplicado a la generación de escenarios complejos en torno a concepciones de sexualidad y género en alumnos de escuelas medias. +Sebastián Ezequiel SustasLucas KlobovsLiliana Pascual“El análisis de redes sociales como herramienta para focalizar la intervención en entornos rurales a través de políticas públicas. +Nicolás Vladimir Chuchco / Cintia Noelia Díaz / María Leonor Pérez BrunoNicolás Sacco
RAESTA 2 - Año 2 (2015)
Editorial
Artículos
Bruno De SantisConstrucción de un índice del nivel socioeconómico del hogar urbano en la República Argentina mediante el análisis de correspondencia múltiple y escalamiento óptimo. +María Fernanda Artola / Iván Redini BlumenthalOrientaciones de futuro laboral y educativo de estudiantes secundarios. Análisis multivariado en un diseño muestral complejo. +Rosario AustralMarcelo Bergman / Diego Masello / Christian Arias / Guadalupe Peralta AgüeroUn ejemplo de diseño cuasi experimental: uso de la regresión logística binaria en la construcción de un grupo de comparación para la evaluación de impacto de un programa social. +Horacio ChitarroniMetodología estadística para la estimación de las superficies sembradas con cultivos extensivos - método de segmentos aleatorios. +Norberto V. Rodríguez / Julieta Mirensky
RAESTA 1 - Año 1 (2014)
Editorial
Artículos
La pérdida de valor de las credenciales educativas en el mercado de trabajo Argentino 1995-2001. Una respuesta desde los métodos estadísticos. +Florencia SourrouilleLos docentes en la Encuesta Permanente de Hogares. Notas metodológicas para su identificación y estudio. +Leandro BottinelliEspecificación del modelo, datos faltantes y casos atípicos: la “trastienda” de una investigación basada en el análisis de la varianza. +Luisa IñigoAna María Capuano