La pérdida de valor de las credenciales educativas en el mercado de trabajo Argentino 1995-2001. Una respuesta desde los métodos estadísticos.
En este trabajo se sostiene que durante la segunda mitad de la década de 1990 se desarrolló un proceso de pérdida de valor de las credenciales educativas de los trabajadores con nivel de estudios secundario completo o mayor. Como a su vez en el período se incrementó la desigualdad salarial se sostiene que lo que se observa es un fenómeno de dos aristas: de devaluación educativa y segmentación del mercado de trabajo. Para realizar estas afirmaciones se utilizan regresiones lineales múltiples para el cálculo de premios salariales. Dado que la fuente utilizada es una muestra y el universo es pequeño se utilizan pooles de datos para ampliar la cantidad de muestra disponible y mejorar las estimaciones. Se desarrolla una metodología cuyo objetivo es poder decidir desde el punto de vista estadístico si los pooles de datos pueden ser utilizados o no en cada problema de trabajo y como trabajar con ellos, y así poder utilizar los recursos disponibles bajo el control de métodos estadísticos.
Los docentes en la Encuesta Permanente de Hogares. Notas metodológicas para su identificación y estudio.
El estudio de los docentes como colectivo laboral en Argentina puede ser realizado con precisión a partir de los Censos Nacionales de Docentes. Estas fuentes de información son específicas del sector educativo y, por lo tanto, las más idóneas para la caracterización detallada de los cargos, horas, funciones, trayectorias y formación de los docentes. Sin embargo, sus principales limitaciones son la periodicidad decenal y las dificultades para comparar a los docentes con otros grupos laborales. La Encuesta Permanente de Hogares, fuente diseñada para caracterizar y monitorear la inserción laboral de la población, permite suplir las limitaciones mencionadas en el estudio de los ocupados en las actividades de enseñanza. Sin embargo, tiene ciertas características y limitaciones que resultan importantes tener en cuenta al utilizarla para estudiar el colectivo docente. Este artículo analiza la fuente en cuanto sus potencialidades para el estudio de este grupo laboral. Concluye que es consistente para el estudio de la evolución del empleo docente.
Especificación del modelo, datos faltantes y casos atípicos: la “trastienda” de una investigación basada en el análisis de la varianza.
El artículo está centrado en la discusión de aspectos metodológicos de la investigación de tesis de la autora. En el campo de los estudios sobre la distribución personal del ingreso y los mercados de trabajo resulta habitual el análisis de la regresión del ingreso personal contra diversos atributos de los perceptores y sus ocupaciones. Este análisis tiene por requisito la resolución de cuestiones referidas a: la definición del modelo en que estará basado, el tratamiento que se dará a los casos sin información y los procedimientos mediante los que se evaluará y, eventualmente, corregirá la influencia de los casos extremos sobre los parámetros estimados. El artículo refiere qué decisiones fueron tomadas en la investigación a este respecto, fundamentando las razones y describiendo su impacto sobre los resultados obtenidos.
¿Qué son los Indicadores? Perspectivas y usos diferentes.
El presente artículo tiene como objetivo presentar las diferentes perspectivas y usos de los indicadores, por un lado, desde las ciencias sociales y por otro desde lo que se denominó “Movimiento de Indicadores Sociales”. En términos generales, el uso de los indicadores ha sido utilizado desde el enfoque de las ciencias sociales para medir empíricamente conceptos teóricos que permitan el abordaje empírico a los fenómenos sociales. Sin embargo, los indicadores son también utilizados desde una perspectiva más pragmática, principalmente por los organismos de estadística y organismos internacionales. A través del artículo se presentan los diferentes recorridos realizados por las perspectivas mencionadas. En la primera parte se describe la medición empírica de conceptos a través de indicadores en los principales referentes de las ciencias sociales. En la segunda parte se describe el contexto de surgimiento y el desarrollo de lo que se denominó “Movimiento de Indicadores Sociales” como otra forma de aproximación al estudio de la realidad social a través de indicadores. En la tercera se problematiza las diferencias de ambas perspectivas en cuanto a los objetivos y el método que utilizan y se presenta como conclusión la importancia de vincular ambas perspectivas.
Aportes al estudio de la opinión pública en las elecciones presidenciales 2007 en Argentina.
El presente trabajo intenta explorar la creciente importancia que los estudios de opinión pública han comenzado a tener durante las últimas décadas. En este sentido, se busca brindar un aporte a la investigación dentro de una actividad que siempre ha estado más bien alejada del ámbito académico, en especial en los estudios relacionados con los procesos electorales. Asimismo, el trabajo intenta develar la notable injerencia que los medios de comunicación tienen en los procesos electorales de los últimos años, demostrándose que se trata de una tendencia que va tomando cada vez más impulso. Finalmente, se analizaran cuestiones que resultan un aporte para diagnosticar los cambios en las percepciones de la ciudadanía durante la etapa previa y posterior a una elección.
Construcción de un índice del nivel socioeconómico del hogar urbano en la República Argentina mediante el análisis de correspondencia múltiple y escalamiento óptimo.
El trabajo presenta la construcción de un índice que tiene como finalidad asignar a cada hogar urbano de la República Argentina un nivel socioeconómico. Se piensa al índice como una variable latente (no observable) y se aplica el análisis de correspondencia múltiple, método exploratorio de estadística multivariada, para obtener los ponderadores (pesos) de las modalidades de las doce variables seleccionadas.
El índice se compone de variables relativas a las características de la vivienda, la condición laboral y educativa del jefe de hogar y del cónyuge. La metodología se aplica a la Encuesta Nacional de Gasto de los Hogares 2012/2013 (Instituto Nacional de Estadísticas y Censos). Una vez estimados los puntajes de la variable latente para los hogares urbanos, se establecen los quintiles socioeconómicos y se asigna a cada hogar un quintil. Finalmente, se analizan las características de cada uno de los quintiles obtenidos y se indican las fortalezas y limitaciones de la metodología.
Orientaciones de futuro laboral y educativo de estudiantes secundarios. Análisis multivariado en un diseño muestral complejo.
En este artículo se analizan las orientaciones de futuro laboral y educativo de los estudiantes que a fines de 2008 cursaban el último año de estudio en las escuelas estatales de la Ciudad Autónoma de Buenos Aires. En primer lugar, se describen las orientaciones de futuro hallándose una prevalencia de proyectos educativo-laborales entre los estudiantes y una anticipación de obstáculos que resulta más pronunciada en el plano laboral que en el educativo. Luego, mediante un análisis de regresión logística multivariada, se compara la influencia relativa de distintos atributos sociales, escolares, biográficos y de la oferta educativa sobre los objetivos de tipo profesional. Entre los principales resultados se halla que las diferencias de género muestran contundencia en la priorización de un objetivo profesional. La modalidad del plan de estudios también emerge como un aspecto clave en los horizontes de futuro, observándose un hiato entre la formación bachiller-comercial y la técnica, donde prevalecen expectativas de inserción laboral directa luego del egreso. Otro hallazgo es que en el plano educativo los horizontes de profesionalización adquieren una difusión más amplia e independiente del origen social educacional, como reflejo de un contexto donde están dadas ciertas condiciones para el acceso masivo a la educación superior. Por otra parte, en el trabajo se enfatiza la importancia de considerar la complejidad del diseño muestral en la instancia de análisis de los datos. Para ello se comparan los resultados obtenidos con estimadores que consideran la complejidad de diseño muestral con otros “naive”, reflexionando acerca de las implicancias epistemológicas que esto conlleva en la puesta a prueba de hipótesis en el análisis bivariado y multivariado.
“Condiciones de socialización, entorno y trayectoria asociados a la reincidencia en el delito”.
En la actualidad el delito y la punición son analizados desde diferentes enfoques, ya que además de estar en crisis son temas a los cuales se les busca encontrar respuestas y soluciones. Es sabido entre los expertos que estudian estos tópicos que dentro de las cárceles la población es mayoritariamente joven, con bajos niveles de educación y provenientes de clases socioeconómicas medias/bajas y bajas, caracterizadas, entre otras cosas, por los bajos niveles de ingreso.
Teniendo en cuenta estas características podría pensarse que la vinculación explicativa de una conducta delictiva está dada por la asociación entre la condición de pobreza de un hogar y/o de sus integrantes y las probabilidades de comisión de delitos y la reincidencia en los mismos. Sin embargo, en este documento proponemos la existencia de una relación mucho más compleja. Por lo tanto, cabe preguntarse en relación al delito y a la reincidencia en el mismo, ¿qué tan asociados están esos factores a quienes incurren nuevamente en una conducta delictiva y al nivel de violencia al momento de perpetrar un delito?, finalmente, ¿qué factores son estos?
Para responder a estas preguntas se realizó un modelo de análisis multivariado basado en una regresión logística, en el cual se incorporaron variables relacionadas con los entornos o contextos de socialización temprana de los sujetos así como la trayectoria en instituciones como los institutos de menores. Los datos utilizados pertenecen a la Encuesta a Población en Reclusión de 2013, en la cual para Argentina se aplicaron más de mil encuestas personales a presos condenados por la justicia federal y ordinaria de la Capital así como por la justicia de la Provincia de Buenos Aires. Cabe destacar, además, que este fue un estudio que abarcó un conjunto de otros cinco países de la región: Brasil, Chile, El Salvador, México y Perú.
Un ejemplo de diseño cuasi experimental: uso de la regresión logística binaria en la construcción de un grupo de comparación para la evaluación de impacto de un programa social.
Este artículo trata acerca del empleo de la regresión logística binaria para la construcción de un grupo de comparación útil para la evaluación de impacto de un programa social. Se basa en una experiencia de aplicación real de tal procedimiento.
En la primera parte se aborda brevemente la problemática que plantea la implementación de diseños puramente experimentales en el caso de la evaluación de políticas públicas de contenido social y la alternativa de emplear modelos cuasi experimentales con un grupo de comparación construido estadísticamente. También se ponen en consideración algunas cuestiones inherentes a los diseños con doble medición, al tiempo que se abordan las dificultades que plantea la frecuente ausencia de una línea de base en el caso de los programas sociales. Asimismo, se explicitan los requisitos que debieran cumplimentar los grupos de comparación construidos mediante modelación estadística.
La segunda parte se refiere a las características del procedimiento estadístico empleado (la regresión logística binaria) y su utilidad específica para la obtención de grupos de comparación, con las limitaciones e inconvenientes que plantea, las alternativas posibles para sortearlos y los recaudos a adoptar. Finalmente, en la última parte se exponen los resultados provenientes del ejemplo de aplicación de este procedimiento conjuntamente con la interpretación de los mismos.
METODOLOGIA ESTADISTICA PARA LA ESTIMACION DE LAS SUPERFICIES SEMBRADAS CON CULTIVOS EXTENSIVOS - METODO DE SEGMENTOS ALEATORIOS.
El conocimiento de la superficie sembrada con cultivos extensivos es de relevancia estratégica para el país y necesita ser estimada en forma objetiva dos veces al año para las principales Provincias Argentinas. El método aquí propuesto es el de observar –con el significado literal de la palabra- una muestra de segmentos que se definen, como relativamente pequeñas áreas que toman la forma de polígonos rectangulares, sin consultar a los dueños de las tierras, a los productores ni a ninguna persona relacionada con las explotaciones que contiene el segmento.
La selección original es de puntos aleatorios dentro de estratos de uso homogéneo del suelo, que luego se los transforma en segmentos. Es obvio que gran parte de los puntos caerán en lugares que no se pueden acceder con un vehículo y para poder llevar a cabo la observación es necesario trasladar el punto hasta el camino más próximo y allí conformar el segmento. Desde el punto de vista de la teoría del muestreo se reconoce que el procedimiento de trasladar origina un sesgo el cual es un error no debido al muestreo.
La contrapartida es que el método tiene importantes ganancias, entre ellas: a) muy alta confiabilidad de los datos por provenir de observaciones “in situ” hechas por expertos, b) no hay error en la medida de las superficies por utilizar tecnología satelital, c) una vez definido el segmento el Sistema de Posicionamiento Global (GPS) permite controlar el operativo y anula el error de ubicación de los segmentos en futuros operativos, d) las muestras son altamente comparables en el tiempo, e) los resultados se obtienen en breve tiempo, en general no más de tres meses, f) reducción notable del presupuesto al no existir revisitas.
El método incorpora nuevas tecnologías, entre ellas: imágenes satelitales, Sistemas de Información Geográfica (GIS), el GPS, el uso del Índice de Vegetación de Diferencia Normalizada (NDVI), programas de procesamiento de la información y protocolos estrictos de procedimientos.
Desempeño de las PyME industriales argentinas, 2005-2011: Medición de eficiencia en la producción a través de un enfoque no-paramétrico.
Este trabajo mide la eficiencia en la producción de las PyME industriales argentinas a partir de la productividad total de los factores, para el período 2005-2011, utilizando datos a nivel empresa, y aplicando el enfoque Análisis Envolvente de Datos (DEA por sus siglas en inglés) basado en el trabajo de Farrell (1957) y las extensiones introducidas por Charnes et al (1978) y Banker et al (1984). Se busca generar un aporte desde el punto de vista metodológico, como antecedente en lo referido a cómo puede medirse la eficiencia de las PyME industriales argentinas en base a información estadística disponible, y explorar cuáles son los factores determinantes de la misma, ya que hasta el momento hay un vacío de información en este sentido. A partir de esto, se explora la asociación de este nivel de eficiencia con factores exógenos a las empresas o internos a las mismas como potenciales determinantes del mismo. Se encuentra que las PyME localizadas en las regiones del país de mayor desarrollo relativo y concentración de la actividad económica tienen un nivel de eficiencia en promedio mayor al resto. Mientras que, sorprendentemente, no hay evidencia suficiente para suponer que el sector de actividad de pertenencia está relacionado con el nivel de eficiencia en la producción. Por otro lado, contrariamente a lo esperado, las empresas más grandes, que exportan, y que solicitan y obtienen créditos bancarios, registran en promedio menores niveles de eficiencia que el resto, aunque esto podría explicarse por el hecho de que estas firmas están más capitalizadas, lo que, al incrementar su dotación del factor de producción capital, impacta negativamente en su eficiencia técnica de producción.
Análisis multivariado aplicado a la generación de escenarios complejos en torno a concepciones de sexualidad y género en alumnos de escuelas medias.
En el presente artículo se exponen aspectos analíticos y metodológicos de la aplicación de diversas técnicas de análisis de datos multivariados empleadas en una investigación sobre salud sexual y reproductiva y educación sexual. Se propone la categoría de escenarios complejos como construcción analítica que permite poner en vinculación concepciones, creencias y actitudes sobre sexualidad, diversidad sexual, género y aborto en base a un relevamiento por encuestas estructuradas en mujeres y varones adolescentes escolarizados en el nivel medio de Argentina realizado durante el segundo semestre del 2012. Dicho relevamiento tuvo como propósito principal indagar y explorar las formas en que determinadas concepciones sobre la sexualidad y el género de los alumnos se vinculan con modelos de educación sexual, las temáticas priorizadas en dichos abordajes, las formas en que se establecen los vínculos con docentes y adultos, los vínculos afectivos intrageneracionales, y las instancias de subjetivación juvenil. Se aplicaron una serie de técnicas estadísticas multivariadas: análisis de componentes principales, análisis de cluster por el método de K-medias y, fundamentalmente, el análisis de correspondencias múltiples para la generación de los escenarios complejos.
Las elecciones a Presidente de Argentina en 2011 y 2015.
La elección a Presidente en Argentina de 2011 tuvo como ganadora a la candidata por el Frente para la Victoria Cristina Kirchner con una amplia diferencia respecto al segundo. El triunfo de la candidata tiene diferentes explicaciones causales desde el punto de vista de las motivaciones del voto por parte del electorado. A través de la presente investigación se intenta identificar las variables condicionantes y jerarquizarlas. Las características socio demográficas del ciudadano no tienen la influencia de otros momentos. En cambio, variables relacionadas con la gestión, el posicionamiento de los candidatos y el vínculo entre Néstor Kirchner y su esposa adquieren mayor protagonismo como condicionantes del voto.
El triunfo de Mauricio Macri en la elección presidencial de 2015 también tiene sus explicaciones causales. Sin entrar en la profundidad de la elección de 2011, se encontraron aspectos ideológicos y vinculados al consumo como elementos motivadores del voto.
Las estadísticas educativas y los desafíos futuros: un sistema de información por alumno.
Este trabajo analiza tanto los antecedentes como las características actuales del sistema de información estadística del sistema educativo argentino. Se plantea también el camino futuro de este sistema, teniendo en cuenta los cambios tecnológicos que tuvieron lugar en nuestro país en los últimos años.
Actualmente, el sistema nacional de información educativa está basado, principalmente, en el Relevamiento Anual, operativo censal que recoge con un corte anual la información consolidada a nivel nacional sobre las principales variables del sistema educativo, exceptuando las universidades. Este sistema garantiza una información homogénea y comparable para todo el ámbito nacional.En la actualidad el sistema de información educativa enfrenta nuevos desafíos producto de un sistema educativo complejo y en constante transformación. Además, el Relevamiento Anual presenta varias limitaciones y solo permite analizar en forma parcial los nudos críticos del sistema educativo. Para paliar estas limitaciones, durante los años 2013 y 2015, se desarrolló un Sistema Integral de Información Digital Educativa —SInIDE—, basado en información nominal de los alumnos. Este nuevo sistema articula y compatibiliza los requerimientos de información de las distintas instancias de gestión en los niveles nacional y jurisdiccional y permite que las instituciones educativas desarrollen a través de este sistema sus propios procesos administrativos y pedagógicos. Su potencialidad radica en la posibilidad de acelerar todos los procesos y de recoger datos adicionales para diagnosticar el funcionamiento del sistema educativo y las trayectorias educativas de los alumnos, tanto a nivel de los establecimientos como a nivel provincial o nacional. Además, permite la construcción de nuevos indicadores para evaluar la situación del sistema educativo en todo el país, fortaleciendo las políticas que se llevan a cabo en el marco de la Ley de Educación Nacional.
El análisis de redes sociales como herramienta para focalizar la intervención en entornos rurales a través de políticas públicas.
Este trabajo muestra los resultados mediante la aplicación de un instrumento de recolección de datos reticulares para un estudio de línea de base y evaluación de políticas públicas en entornos rurales, a fin de describir, medir y comparar las formas de las asociaciones entre los agentes involucrados de dos cooperativas.
Los objetivos de la ponencia radican en describir y caracterizar las redes de asociaciones de pequeños productores rurales en un contexto social delimitado, y evaluar la viabilidad de complementar los análisis estadísticos cuantitativos tradicionales con la metodología del análisis de redes sociocéntricas, para focalizar las formas de intervención y detectar asociaciones latentes y potenciales.
Los resultados obtenidos al aplicar este instrumento en dos agrupaciones de pequeños productores rurales del Noroeste argentino, beneficiarios de un programa social en el año 2014, muestran dos grafos multiplexados diferenciados. Mientras que en la primera red la forma de las asociaciones para movilizar recursos estratégicos se encuentra restringida por la autoridad de los referentes de la organización, en la segunda se observa una distribución más equitativa y menos autoritaria de los vínculos, así como una intermediación menos centralizada.
Se concluye que esta metodología ha sido adecuada para describir las fuerza, dirección y circulación de las relaciones entre los nodos de las agrupaciones relevadas, así como la existencia de asociaciones potenciales que no sean efectivizado. De esta forma la toma de decisiones se ve beneficiada al disponer de información específica, que permite detectar la necesidad de fortalecer vínculos, así como la posibilidad de identificar nodos y subgrupos que centralizan la intermediación y los recursos o que pueden desarrollar una mejor circulación de los mismos a causa de sus posiciones estratégicas en las redes.
Las clases sociales según los censos de población de 1991 y 2001.
El artículo presenta una metodología para la reconstrucción de las series del Nomenclador de Condición Socio-Ocupacional y el esquema de clases de Torrado a lo largo del período 1980-2001, durante el cual los cambios en los sistemas clasificatorios de las variables involucradas en su construcción presentaron importantes cambios. Se utilizaron los datos secundarios del estudio “Estructura Social Argentina” del Consejo Federal de Inversiones para el censo de 1980 y los datos publicados por el Instituto Nacional de Estadística y Censos de los censos de población de 1991 y 2001, para el Total del País.
La investigación aborda tanto las cuestiones metodológicas enfrentadas a la realidad de la oferta estadística en Argentina así como también aspectos teóricos sobre la temática de la estructura social. Se realiza un detallado análisis de las fuentes existentes que permiten la construcción de series lo más homogéneas posibles en términos metodológicos con el objetivo de que muestren los cambios de la estructura social entre fines de los cuarenta y la actualidad. Se analizan también los resultados alcanzados. En lo que hace a este aspecto, sin embargo, la profundidad de la indagación es menor.
El aporte permite continuar y armonizar, con las dificultades y advertencias metodológicas que implica, los trabajos de Germani (1955) y Torrado (1992) y el análisis de la estructura social Argentina según datos secundarios cuantitativos.
Palabras clave: Condición Socio-Ocupacional; clases sociales; censos de población; estructura social argentina; mercado de trabajo; ocupación; empleo.
RAESTA 1 - año 1 (2014)
Artículos
La pérdida de valor de las credenciales educativas en el mercado de trabajo Argentino 1995-2001. Una respuesta desde los métodos estadísticos.1
Florencia Sourrouille2

1. Presentación
La relación entre el nivel educativo de la población y su inserción en el mercado de trabajo es una temática que recorre extensamente la investigación social. Esta se aborda desde distintas perspectivas. En este artículo se propone indagar acerca del posible desajuste entre el nivel educativo de la fuerza de trabajo y el correspondiente a los requisitos de calificación de los puestos, lo cual podría estar manifestando un proceso de devaluación de las credenciales educativas.
La coexistencia durante la década de 1990 en el mercado de trabajo Argentino de un escenario macroeconómico propicio para que se pueda desarrollar un proceso de pérdida de valor de las credenciales educativas3 así como de un aumento de la desigualdad salarial hace que esa década, y en particular el período 1995 - 2001, tenga un interés particular para el análisis.
En este momento aparece, por un lado, un escenario favorable para que pueda existir un proceso de pérdida de valor de las credenciales educativas (conocido como devaluación educativa) dada la política de apertura de la economía con desempleo creciente e inestabilidad laboral (Altimir y Beccaria, 1999) junto a una oferta creciente de fuerza de trabajo con alto nivel educativo. Este hecho en particular estaría dando cuenta de una incapacidad del mercado de trabajo para absorber a la fuerza de trabajo más educada. Pero además se observa en ese mismo momento que las brechas de ingresos se amplían, es decir, existe otro proceso que es el de diferenciación de la fuerza de trabajo a partir de los salarios. Esto último pone en evidencia que no es toda la fuerza de trabajo la que ve devaluada su inserción laboral (si fuera así se esperaría una disminución de las brechas salariales) sino que una parte ve devaluada su inserción, y otra la mejora, pudiéndose observar una segmentación4 del mercado de trabajo.
Así, este aumento de la desigualdad salarial plantea debates acerca de las implicancias que tiene en relación a los trabajadores más educados. Dado que a lo largo de la década de 1990 aumento del nivel educativo de la población en general y de la fuerza de trabajo en particular, pero que se registra un estancamiento de los puestos de trabajo profesionales, se discute si el mayor nivel educativo registrado en la fuerza de trabajo es requerido para el puesto o no. En el caso de no ser requerido, el trabajador se vería forzado a aceptar puestos por debajo de su nivel para evitar caer en el desempleo.
Este artículo se enmarca en la tesis de Maestría “La devaluación educativa en el mercado de trabajo Argentino 1995-2001. Una aproximación metodológica a partir de la técnica de pool de datos” elaborado por la autora y dirigida por Fernando Groisman en el marco de la Maestría en Generación y Análisis de Información Estadística (UNTREF-INDEC). A diferencia del trabajo de tesis donde se aborda la problemática planteada en el título de manera extensa, en el artículo que se presenta se trabaja solamente un aspecto específico de la problemática que es la discusión en torno a si el nivel educativo de la fuerza de trabajo es requerido o no para los puestos de trabajo en los cuáles se desempeñan desarrollando una metodología para poder dar cuenta de este fenómeno.
En primer lugar, se enuncian brevemente las distintas perspectivas con las cuáles se aborda la temática. Luego se presenta la hipótesis de trabajo y los aspectos metodológicos. En tercer lugar se desarrolla la metodología que se utiliza para el análisis. Dado que, como se observará en el desarrollo del problema, el universo de trabajo definido es pequeño y la fuente de datos que se utiliza es muestral, provocando esto que las estimaciones estén sujetas a errores muestrales grandes, se utiliza la técnica de pool de datos para resolver este problema. En este apartado se propone una metodología para poder utilizar esta técnica. En cuarto lugar se presentan los resultados y por último las conclusiones.
2. Perspectivas teóricas
Las perspectivas más sobresalientes que abordan esta temática, se pueden agrupar de la siguiente manera:
De un lado, las que dicen que el aumento del nivel educativo de la fuerza de trabajo se debe a que el mercado laboral requiere de una fuerza de trabajo más educada (González Rozada 1196, Gasparini 2003). Estos autores afirman que lo que se observa como un aumento del nivel educativo de la fuerza de trabajo se debe a que existen nuevos requerimientos del mercado laboral que provienen de cambios tecnológicos. Otros autores también, siguiendo una línea similar, sostienen que la complejización de las (actividades laborales demanda de una escolarización más extensa (Argumedo 1996, Gallart 1997). Lo que se sostiene es que existe un desajuste entre la educación formal y los cambios relacionados con la organización del trabajo. En este desajuste existe una responsabilidad del sistema educativo en no estar estrechamente articulado con el mercado de trabajo.
Una lectura diferente de la anterior es la que argumenta que el mercado de trabajo no tiene la capacidad de absorber a la fuerza de trabajo más educada, lo cual implica que exista una subutilización de la fuerza de trabajo por calificación, desaprovechándose las potencialidades de los trabajadores y dándose una pérdida de valor de las credenciales educativas.
Aquí lo que se discute es si el mercado de trabajo requiere de una fuerza de trabajo más educada dada la complejización de las actividades por cambios tecnológicos o si por el contrario hay una falta de capacidad del mercado laboral para absorber a la fuerza de trabajo más educada (Maurizio 2001, Salas 2005, Filmus 2001, Pérez 2005, Waisgrais 2005). Esto implicaría considerar que existe una subutilización de la fuerza de trabajo por calificación.
Por último Groisman (2003) propone que existe un proceso por el cual se dan dos fenómenos tiempo: la pérdida de valor de las credenciales educativas a la par que la segmentación del mercado de trabajo. Así, entre la fuerza de trabajo de mayor educación se verifica una diferenciación entre quienes logran poder acceder a puestos que están acordes a su calificación y quiénes no. En esta perspectiva se inscribe este estudio.
3. Hipótesis de trabajo y aspectos metodológicos
La hipótesis que guió la tesis de maestría fue que se habrían cubierto una cantidad relevante de puestos de trabajo con personas con calificaciones superiores a las necesarias que no impidió que progresara un proceso de heterogeneización salarial entre trabajadores del mismo nivel educativo.
La pregunta que se intenta responder en particular en este artículo es cuánto de la diferenciación salarial se debe a las distintas formaciones educativas de las personas y cuánto a las oportunidades del mercado de trabajo. ¿Cuáles son las variables que explican la diferenciación salarial? ¿Las características de formación de las personas medidas a partir de su nivel educativo, o las del puesto de trabajo? El nivel educativo de las personas ¿es requerido para el puesto de trabajo que ocupan?
Para esto se definen dos períodos de tiempo (1995 – 1998 y 1999 – 2011) en función de la evolución del PIB, sea ascendente o descendente. La fuente de datos que se utiliza es la Encuesta Permanente de Hogares (EPH) dado que se encarga de relevar la situación ocupacional y sociodemográfica en forma periódica en la Argentina.
El universo de trabajo que se utilizó en la tesis y sobre el que se reflexiona en este artículo está constituido por los asalariados plenos del sector privado de entre 25 y 55 años en aglomerados de 500.000 y más habitantes con nivel educativo secundario completo o mayor. Quedan exceptuados los trabajadores del sector estatal, la administración pública, educación, servicios sociales, de salud, comunales, servicio doméstico.
¿A qué se debe ese recorte? A que la forma de evidenciar si el nivel educativo de la fuerza de trabajo es requerido para el puesto o no se hizo a partir del cálculo de premios salariales. Este hecho vuelve relevante poder medir las diferencias en los ingresos que tengan que ver con el fenómeno que se está estudiando. Centrar el estudio en trabajadores en edad plenamente activa permite evitar introducir el sesgo de quiénes están recién empezando a construir su trayectoria laboral. Captar únicamente al sector privado se vuelve relevante dado que en este se fijan los salarios en forma distinta al sector público. Ceñir el análisis a los aglomerados de 500.000 habitantes y más permite evitar dificultades relacionadas con que en aglomerados pequeños pueden existir dinámicas distintas en relación a la capacidad de obtención de un puesto de trabajo acorde al del nivel educativo que se alcanzó.
Todas estas decisiones, consideradas necesarias para el estudio, provocaron que quede definido un universo pequeño de población y por lo tanto que las estimaciones resulten más imprecisas. Con el objetivo de poder utilizar los recursos disponibles pero a su vez realizarlo bajo el control de métodos estadísticos se utiliza la técnica de pool de datos. Esta consiste básicamente en unir datos originados en distintos relevamientos para sumar casos. El supuesto que avala realizar esta operación es que las variables no han tenido cambios significativos en el tiempo. En este trabajo se desarrolla una metodología para poder definir si las variables han tenido o no cambios significativos en el tiempo y poder decidir de esta manera en que casos se puede trabajar con pooles y en cuáles no, teniendo una medida de cuál es el efecto en los resultados de trabajar con pooles de datos.
En este artículo se presenta la metodología para la encuesta permanente de hogares puntual. En la tesis de maestría citada se presenta también la metodología para la encuesta continua. Igualmente la metodología que aquí se presenta puede ser utilizada para el trabajo con otras encuestas puntuales más allá de la EPH.
4. Desarrollo de la metodología de pooles de datos
Dado que utilizamos como fuente a una encuesta por muestreo (en nuestro caso la EPH), sus estimaciones están afectadas por el error muestral. Según la teoría del muestreo los estimadores tienden a seguir distribuciones normales y a partir del desvío standard se pueden calcular intervalos de confianza, los cuales representan la probabilidad de contener el valor verdadero que se quiere estimar. En el caso de nuestro estudio necesitamos construir intervalos de confianza para poder afirmar si dos estimaciones son significativamente distintas. Por otra parte, las recomendaciones en los manuales metodológicos de la EPH indican que las estimaciones cuyos coeficientes de variación mayores a 10% deben ser tratados con cautela.
Uno de los factores que intervienen en la dispersión y que por lo tanto están implicados en el cálculo de los estimadores y de los intervalos de confianza es la cantidad de casos de la muestra. A mayor dispersión, mayor amplitud del intervalo y será más difícil poder afirmar que dos estimaciones son significativamente distintas. Por lo tanto una estrategia para mejorar la precisión de las estimaciones es ampliar la cantidad de casos con la que trabajamos.
Para esto es que se propone trabajar con pooles de datos (Kish 1972, 1975). Esta técnica implica construir una base de datos (a partir de una onda original) que agregue registros de ondas subsiguientes con el objetivo de agrandar el tamaño de la muestra. Se basa en el supuesto que las variables utilizadas no tienen cambios significativos en su distribución en momentos cortos de tiempo. A continuación se desarrolla una metodología que permita conocer desde el punto de vista estadístico, si el supuesto de que los datos no tienen cambios significativos en el tiempo se da en la realidad o no, y de ser así, evaluar si es posible controlarlo.
En primer lugar, hay algunos criterios a cumplir y ajustes a realizar. Se evalúa la estructura de las muestras con el objetivo de determinar si se registran diferencias en las ondas con las que se quiere construir los pooles de datos (Mayo 1996 1998 – Mayo 1999 2001) en cuanto a su cobertura geográfica, el tamaño de la muestra y posibles problemas surgidos en el relevamiento.
En relación al primer punto se observa que los aglomerados de 500.000 y más habitantes (los definidos por nuestro universo) incorporados en la EPH en Mayo 96-98-99-01 se mantienen en todas las ondas.
Tampoco existen diferencias en el tamaño de la muestra. Si bien en el aglomerado de Gran La Plata se reduce la muestra el 50%, esto ocurre recién en 1999, por lo tanto para los pooles Mayo 96 98 y 99 01 el aglomerado tiene el mismo tamaño al interior de cada pool.
En Octubre de 1996 se descartó la onda de Gran Córdoba por mala calidad de los datos. En Agosto de 1998 no se relevó el aglomerado de Gran Mendoza. En esta misma onda surgieron dificultades en 5 áreas de los partidos del GBA que hicieron perder información. Al trabajar, esto llevó a utilizar las ondas de Mayo y no de Octubre.
En cuanto a la estructura de los ponderadores lo que se observa en las ponderaciones de los aglomerados con 500.000 habitantes y más para la población de entre 25 y 55 años es que en la muestra del aglomerado Gran Buenos Aires (GBA) cada caso representa a al menos 3 veces más de personas que en el resto de los aglomerados. Motivo por el cual los ponderadores deben ajustarse para que respeten esta distribución.
Cuadro N°1
Valores mínimo, máximo, promedio y desviación típica del ponderador según aglomerado
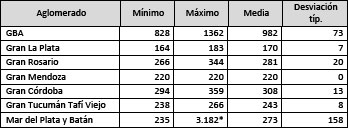
Nota(*)1 caso. (5 registros / 736 están por encima del valor 700).
Propuesta de ajuste de los ponderadores
Una vez aumentado el tamaño muestral y obtenidas en consecuencia estimaciones más precisas se deben ajustar los ponderadores. Hay dos tipos de ajustes necesarios:
Por un lado, uno que mantenga el tamaño de muestra obtenido a partir de haber generado el pool de datos. Esto es necesario para mejorar la precisión de las estimaciones. Por otro lado, como estimaremos premios salariales a partir del uso de regresiones lineales múltiples, se necesita que ese ponderador no expanda los casos muestrales al total poblacional (dado que el tamaño de la muestra incide en los test de hipótesis que se realizan para evaluar si las afirmaciones son significativas desde el punto de vista estadístico o no). El último requisito es que respete el valor relativo de cada caso (los casos aportados por GBA representan a mayor población de los aportados por otros aglomerados). Estas necesidades quedan expresadas en el siguiente ponderador:
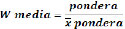
Al dividir al valor original del ponderador por su propia media, la suma de wmedia es igual al nuevo tamaño muestral.
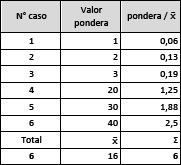
En el siguiente ejemplo se observa cómo, suponiendo valores distintos de la variable original pondera, al dividir por su media se cumplen los requisitos enunciados: la suma de todos los casos divididos por su media vuelven a reconstruir el valor total obtenido por haber pooleado las dos muestras (1/16+2/16+3/16+20/16+30/16+40/16= 96/16=6), se mantienen los pesos relativos (2,50 es el doble que 1,25 así como 40 es el doble que 20), y no se expande al total poblacional.
Cuadro N°2
Ponderación corregida
Por otro lado, al momento de estimar un N, necesitamos realizarlo con un ponderador que expanda los datos al total poblacional. Con más casos se está estimando a la misma población, siendo esta una estimación más precisa. Por lo tanto hay que ajustar al ponderador en función del aumento de los casos muestrales. Este queda dado de la siguiente manera:

Donde
n1= cantidad de casos muestrales del primer relevamiento
npool= la cantidad de casos del pool resultante.
Como se observa, se achica el ponderador de forma proporcional a la cantidad de casos de cada onda. Si ambas ondas aportan los mismos casos será 0,5.
5. Pruebas de hipótesis acerca de la distribución de las variables.
Con estas se busca probar desde el punto de vista estadístico la afirmación de si las muestras fueron obtenidas de la misma población o de poblaciones con similares características. Así, si esta afirmación no puede ser rechazada, es un argumento fuerte para realizar el pool de datos. Esto porque implica que la distribución de las variables a utilizar es lo suficientemente similar para que se pueda afirmar que el hecho de haber sido relevados los datos en dos momentos distintos del tiempo no está incidiendo en los resultados.
Entonces para seleccionar la prueba de hipótesis que más se ajuste a nuestra necesidad partimos de los siguientes enunciados: tenemos 2 o más muestras, en este caso independientes, las cuáles queremos saber si provienen de poblaciones con la misma distribución.
La afirmación que se pretende testear (que las dos muestras fueron extraídas de poblaciones con la misma distribución) queda expresada de la siguiente manera:
H0: La distribución de las variables es =.
Ha: La distribución de las variables es distinta.
Nuestro objetivo es no rechazar la H0 demostrando que las distribuciones no son significativamente diferentes. Esto implica una Sig> 0,05.
Las pruebas no paramétricas que podrían utilizarse para esto son principalmente el Test U de Mann Whitney, la Z de KolmogorovSmirnov y la prueba de las rachas de Wald-Wolfowitz. Estas pruebas, a diferencia de la t para muestras independientes, no tienen algunos supuestos como por ejemplo el de distribución normal, varianzas iguales, o la necesidad de una distribución intervalar. Se pueden utilizar por lo tanto con variables categóricas.
Cuadro N°3
Pruebas no paramétricas seleccionadas según características
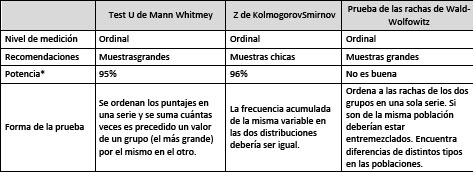
*Probabilidad de no rechazar la Ho cuando es falsa.
La potencia de una prueba es la probabilidad de rechazar la H0 cuando es falsa en la población. En nuestro caso entonces, es importante que la prueba sea potente. Dado que estamos trabajando con una muestra grande (EPH) y que la potencia de la prueba en nuestro caso es importante, seleccionamos el test U de Mann Whitney. Dado que esta prueba de hipótesis requiere un nivel de medición de las variables como mínimo ordinal, se construyeron variables estratificadas que articulan información de sexo, edad y nivel educativo alcanzado. Estas son:
1- Varones por edad continua (Edadvar)
2- Mujeres por edad continua (Edadmuj)
3- Varones por edad en tres intervalos (Vedad)
4- Mujeres por edad en tres intervalos (Medad)
5- Personas de entre 25 y 34 años por nivel en 6 tramos (E1niv6)
6- Personas de entre 35 y 44 años por nivel en 6 tramos (E2niv6)
7- Personas de entre 45 y 55 años por nivel en 6 tramos (E3niv6)
8- Personas de entre 25 y 34 años por nivel en 7 tramos (E1niv7)
9- Personas de entre 35 y 44 años por nivel en 7 tramos (E2niv7)
10- Personas de entre 45 y 55 años por nivel en 7 tramos (E3niv7)
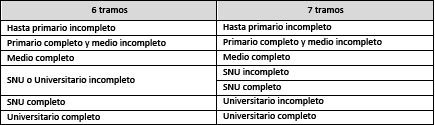
Las categorías de nivel educativo alcanzado en 6 y 7 tramos son las siguientes:
Cuadro N°4
Nivel educativo alcanzado en tramos
Los resultados que arrojan son:
Cuadro N°5
Pruebas de Mann Whitney y niveles de significancia de la población de 25 a 55 años para el conjunto de los aglomerados de 500.000 y más habitantes, por pool según variables seleccionadas
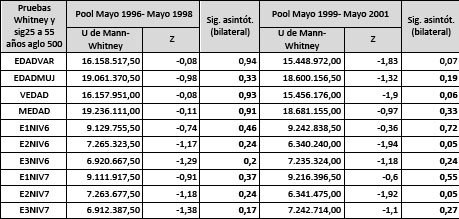
Aquí se observa que el nivel de significancia de las pruebas de hipótesis acerca de la distribución de las variables son iguales o mayores a 0,05, lo cual implica que no se puede rechazar la hipótesis de que las poblaciones de las cuáles fueron extraídas las muestras son iguales. Así, se pueden formar los pooles de datos ya que no se puede decir que las poblaciones sean distintas.
6. Test del efecto de la variable relevamiento de origen.
Analizado ya si la distribución de las variables demográficas de las dos muestras que queremos unir fue extraída de las mismas poblaciones, o de dos poblaciones similares nos centramos ahora en el problema de investigación que trabaja. El objetivo de estos controles es poder evaluar si el relevamiento de origen de los datos tiene o no una incidencia significativa ya directamente en la variable que queremos explicar. Esto implica que este test está directamente vinculado al problema específico que trabajamos. La forma de poder resolver esto es a partir del cálculo de regresiones lineales múltiples donde se incluya en el modelo explicativo a la variable “relevamiento de origen”. Se la incluye como dummy, con valores 0 en el relevamiento año t y 1 en el relevamiento t+1. Así se puede conocer el efecto de haber construido el pool, directamente en la variable cuyo comportamiento se pretende explicar. Si el aporte no es significativo, se puede trabajar perfectamente con el pool. En el caso de tener una incidencia significativa se pueden tomar dos alternativas: a) no utilizar el pool porque el efecto es significativo, b) utilizarlo, manteniendo siempre la variable que lo identifica en los modelos de regresión de manera de tener controlado cual es la incidencia de dicho aporte.
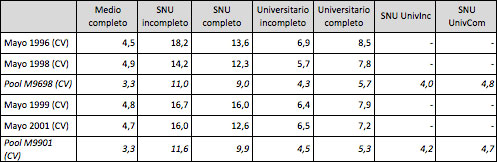
Una vez conformados los pooles de datos se vuelven a calcular los coeficientes de variación para cada nivel educativo utilizando los pooles de datos, y se los compara con los obtenidos sin realizar los pooles, se puede observar la ganancia obtenida en precisión.
Cuadro N°6
Coeficientes de variación del universo de trabajo por nivel educativo alcanzado según relevamiento
7. Desarrollo del problema de investigación a partir de los pooles de datos.
Habiendo realizado los pooles de datos podemos abordar ahora el problema de investigación.
Recordemos que la pregunta que se intenta responder es cuánto de la diferenciación salarial se debe a las distintas formaciones educativas de las personas y cuánto a las oportunidades del mercado de trabajo. Más específicamente: ¿Cuáles son las variables que explican la diferenciación salarial? ¿Las características de formación de las personas medidas a partir de su nivel educativo, o las del puesto de trabajo? El nivel educativo de las personas ¿es requerido para el puesto de trabajo que ocupan?
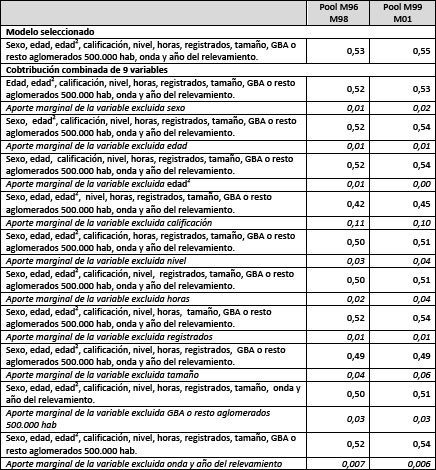
Utilizamos los pooles de datos elaborados para disminuir los errores de muestreo, incluyendo la variable que identifica el relevamiento del cual provienen los datos del pool (onda y año) en el modelo de regresión para, como se ha explicado, poder conocer su efecto. Seleccionamos el modelo que queda conformado por las variables sexo, edad, edad al cuadrado, calificación de la tarea, nivel educativo alcanzado, cantidad de horas de trabajo, si el trabajador se encuentra registrado o no, el tamaño del establecimiento y si está inserto laboralmente en el Gran Buenos Aires o en el resto de los aglomerados de 500.000 habitantes y más. En ambos períodos este modelo explica más del 50% de la varianza de los salarios y la introducción de todas las variables es significativa.
A partir del análisis de las contribuciones marginales, se observar que en general, las variables demográficas como el sexo y la edad (e inclusive la edad al cuadrado, incluida en el modelo para dar cuenta de un posible crecimiento geométrico de los salarios en función de la edad más que de un comportamiento lineal) tienen una escasa contribución marginal al modelo. Las variables con mayor contribución son las que están relacionadas con la calificación de la tarea, el nivel educativo alcanzado, y el hecho de pertenecer al aglomerado Gran Buenos Aires.
Se observa que excluyendo del análisis al nivel educativo y manteniendo al resto de las variables en el modelo, el aporte marginal varía entre un 3 y un 4% en el período 1996-1998 y 1999-2001 respectivamente. Este cambio es más profundo cuando lo que se excluye únicamente es la calificación de la tarea, y se incorporar en el modelo el resto de las variables (entre un 11 y un 10%). Algo similar ocurre con otra característica de la oferta de trabajo (el tamaño del establecimiento) que tiene un aporte mayor al del nivel educativo (4 y 6% respectivamente). El hecho de que sean las variables que caracterizan al puesto de trabajo las que tienen mayor contribución podría alentar la hipótesis que las oportunidades están siendo marcadas por el mercado de trabajo y es sobre estas oportunidades que se integran las personas con su nivel educativo.
Por último la contribución marginal de la variable que identifica al relevamiento de origen de los datos es menor al 1%.
Cuadro N°7
Coeficiente de correlación múltiple r2 en regresiones lineales por MC sobre el logaritmo de los salarios horarios para el universo de trabajo por pool de datos. Modelo seleccionado y contribuciones marginales.
Analizamos a continuación los premios salariales de las variables nivel educativo, la calificación de la tarea y el tamaño del establecimiento dado que son las que tienen las mayores contribuciones al modelo. Mediante el cálculo de coeficientes de regresión, se puede estimar cuanto es en promedio el salario que se agrega a una determinada categoría de trabajadores por sobre el resto. En el caso que estudiamos el indicador es cuánto distintas categorías de nivel educativo aportan al salario. Si trabajadores con características homogéneas en cuánto al sexo, la edad y su inserción en el mercado de trabajo el hecho de variar su nivel educativo no tiene ninguna incidencia en sus salarios, este nivel educativo del trabajador no se considera necesario para el puesto. En cambio, si el nivel educativo es remunerado, se lo considera requerido para el puesto.
Observamos que el premio a la calificación profesional es mayor al del nivel educativo a lo largo de todo el período. El primero, se encuentra por encima del 80%, mientras que el premio al nivel universitario completo, en cambio, nunca llega al 30%. Es la calificación del propio puesto de trabajo la que tiene un efecto mayor en relación a la formación de las personas. Porotro lado se observan algunas diferencias en el comportamiento de las variables:
En el caso de la educación formal, se observa que es el premio a tener el nivel universitario completo el que es significativamente distinto al premio de los trabajadores que tuvieron estudios terciarios no universitarios (más allá de que los hayan finalizado o no) o estudios universitarios incompletos. Sin embargo ninguno de estos últimos podemos decir que tengan premios salariales significativamente distintos a los de quienes han concluido los estudios medios. Al calcular a 2 desvíos estándares los límites inferior y superior de las estimaciones los intervalos se superponen o la estimación no es significativa. Solamente el haber concluidos los estudios universitarios establece una diferenciación salarial.
En cambio, las distintas categorías de calificación si introducen cambios. Se puede observar un aumento progresivo de los salarios en forma de gradiente, a medida que aumenta la calificación del puesto de trabajo. Como se observa en la información del cuadro 4 el premio a la calificación operativa, los salarios son en promedio un 26 y 22% mayores, respecto a la calificación técnica, un 60% y en relación a la calificación profesional, el premio es de un 80%.
Cuadro N°8
Premios salariales horarios, error en la estimación, límites inferior y superior y nivel de significancia para el universo de trabajo por pool de datos. Modelo 3 variables.
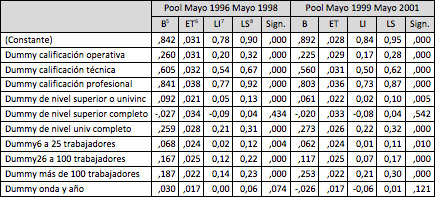
5 Coeficiente beta (representa el premio salarial): Da cuenta del incremento de la variable dependiente respecto al cambio en la variable independiente. Indica cuanto aumenta en promedio el salario ante un cambio en cada una de las variables explicativas incluidas en el modelo. En el cuadro 7 las variables independientes son tipo dummy: asumen el valor de 1 cuando se cumple la condición enunciada en la misma y 0 en caso contrario. Por lo tanto, los coeficientes deben leerse como diferencias respecto de las categorías base de las variables: en el caso de la calificación el valor 0 corresponde a la categoría no calificado, en el caso del nivel educativo al nivel medio completo, y en el caso del tamaño del establecimiento los establecimientos de hasta 5 empleados.
6 Error de la estimación.
7 Límite inferior calculado a 2 desvíos estándares.
8 Límite superior calculado a 2 desvíos estándares.
Como ya se ha dicho, la estimación surgida del análisis de regresión es una estimación de parámetros poblacionales dado una muestra de n observaciones. Lo que interesa demostrar es que el premio salarial dado a una categoría de trabajadores es significativamente distinto al de otra categoría. Para esto debemos poder probar que las estimaciones son distintas para un determinado nivel de confianza, siendo entonces distintas no sólo las estimaciones puntuales sino que no se superpongan las estimaciones contenidas entre el límite inferior y superior del intervalo de confianza.
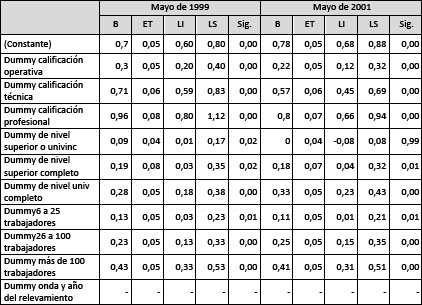
La ganancia que se obtiene utilizando el pool de datos queda demostrada en el cuadro que se presenta a continuación: las estimaciones de los premios salariales obtenidas con y sin pooles de datos son distintas. En primer lugar, difieren en cuanto a los errores de la estimación. Estos se achican cuando se trabaja con pooles respecto a lo que ocurre cuando se trabaja con una sola onda de la encuesta. Además, podemos apreciar que si hubiéramos trabajado sin pooles de datos no podríamos afirmar desde el punto de vista estadístico que los premios a la calificación técnica y profesional fueran significativamente distintos, dado que al comparar las estimaciones con intervalos del 95% de confianza, los límites entre ellas se superponen en ambas ondas: la de 1999 y la de 2001. Sin embargo, al utilizar el pool de datos los intervalos dejan de superponerse y es posible afirmar que son significativamente distintos. Como por otra parte hemos incorporado al modelo la variable que identifica al origen de los datos (la onda y año del relevamiento, podemos observar que el hecho de haber unido observaciones de distintos momentos del tiempo no tiene un efecto significativo (0,12) lo cual avala el uso del pool de datos.
Cuadro N°9
Premios salariales, error en la estimación, límites inferior y superior y nivel de significancia de la calificación de la tarea y el tamaño del establecimiento para el universo de trabajo por año y pool según contribución de variables seleccionadas.
Cuadro N°10 (Continuación)
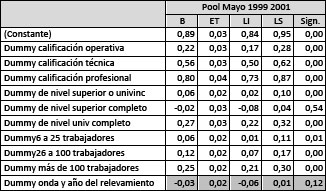
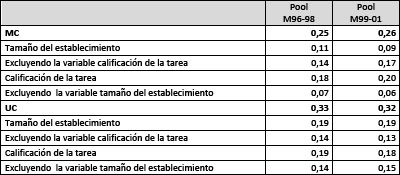
Por último, si tomamos por un lado a quiénes solo han concluido sus estudios medios y por el otro a quiénes han concluidos los estudios universitarios podemos observar que aumentando el nivel educativo las características del puesto de trabajo discriminan más la hora de explicar los salarios. Esta evidencia también permite alentar la hipótesis que, existiendo una importante segmentación de las oportunidades laborales debido a las características de la oferta laboral y no de la demanda, en los sectores de mayor educación deben encontrarse diferencias más importantes.
Cuadro N°11 Coeficiente de correlación múltiple R cuadrado en regresiones lineales por mínimos cuadrados sobre el logaritmo de los salarios horarios para el universo de trabajo por pool según niveles educativos seleccionados
8. Conclusiones
La evidencia encontrada en este breve estudio permite hipotetizar que, ante un escenario de contracción laboral y ampliación del acceso a la educación se puede observar un proceso de dos aristas. Por un lado, desde el punto de vista laboral, la exacerbación de la competencia de trabajadores, lo cual hace bajar los salarios generando un proceso de pérdida de valor de las credenciales educativas. Por el otro, el aumento de la diferenciación entre trabajadores del mismo nivel educativo sugiere la existencia de segmentación laboral.
En este estudio se evalúa cuanto de la diferenciación salarial de los trabajadores de alto nivel educativo se relaciona con las características de la formación de las personas, medidas a partir de su nivel educativo, y cuánto las características de los puestos de trabajo (medidos centralmente a partir de la calificación del puesto de trabajo y el tamaño del establecimiento), con el objetivo de contestar a la pregunta si el nivel educativo de la fuerza de trabajo es requerido o no para el puesto en el cual se desempeñan.
La calificación de la tarea caracteriza a los puestos de trabajo disponibles, siendo este un atributo de la oferta de trabajo (indicador de cuál es la estructura de oportunidades fijada por el mercado de trabajo). Por otro lado, el nivel educativo alcanzado está caracterizando a las personas que demandan trabajo. La brecha en términos de premios salariales entre la calificación de la tarea y el nivel educativo alcanzado da cuenta en nuestra opinión de la diferencia entre las capacidades de las personas y los requisitos del puesto de trabajo. Da cuenta por lo tanto de la subutilización de la fuerza de trabajo y da indicios de un proceso de devaluación de las credenciales educativas debido a que estaría poniendo de manifiesto la existencia de grupos de trabajadores cuyo nivel educativo no parece ser relevante para el puesto de trabajo.
Para poder contestar a esta pregunta existió en un primer momento un inconveniente: al quedar definido un universo pequeño de la población los errores de muestreo eran grandes lo cual no permitía hacer afirmaciones significativas desde el punto de vista estadístico acerca de la pregunta de investigación. De un lado entonces, existía la preocupación acerca de un problema de la realidad Argentina, del otro, la necesidad de utilizar fuentes secundarias y periódicas para analizar la dinámica del mercado de trabajo, pero afectadas, al tratarse de un subuniverso pequeño de la población, por el error muestral. La necesidad del uso de fuentes secundarias, o bien, la imposibilidad de generar relevamientos específicos, ponen al investigador en el problema de cómo predicar sobre problemas con datos que no fueron diseñados para tal fin.
El desarrollo de la metodología de los pooles de datos permite contestar a una pregunta aprovechando la información disponible y realizándolo bajo el control de métodos estadísticos.
Anexo. Variables incluidas en el modelo de regresión.
Trabajamos con el logaritmo del salario horario de la ocupación principal de los asalariados plenos (entre 35 y 60 horas semanales). Para construir la variable se tomaron las siguientes decisiones:
-Se eliminaron los días trabajados mayores a 31.
-Se eliminaron los ingresos < 9.
-Se eliminaron los casos extremos del ingreso mensual correspondientes al universo de trabajo: ocupados asalariados plenos con nivel educativo secundario completo o más, de entre 25 y 55 años, de las ramas 2 a 15 en del sector privado de aglomerados con 500.000 hab y más.
-Se consideraron casos extremos al 1 % más bajo y más alto de la distribución.
-Se construyó el salario horario.
-Se deflactó por el IPC.
-Se construyó la variable logaritmo natural del salario horario.
Se trabaja con las siguientes variables predictoras:

Bibliografía
ARGUMEDO, A. (1996): “El imperio del conocimiento. Impacto de la revolución científico-técnica” en Encrucijadas N°4, UBA, Buenos Aires.
BECCARIA, L, ALTIMIR, O. (1999): “El mercado de trabajo bajo el nuevo régimen económico en Argentina”, Serie reformas económicas N° 28, CEPAL.
FILMUS, D. (2001): “Cada vez más necesaria, cada vez más insuficiente. Escuela media y mercado de trabajo en épocas de globalización”, Santillana, Buenos Aires.
GALLART, M. A. (1997): “Los cambios en la relación escuela-mundo laboral”, en Revista Iberoamericana de Educación Número 15 Micropolítica en la escuela.
GASPARINI, L. (2003) “Argentine’s Distributional Failure.The role of integration and PublicPolicies”, CEDLAS, Universidad Nacional de La Plata.
GROISMAN, F. (2003): “Devaluación educativa y segmentación en el mercado de trabajo del área metropolitana de Buenos Aires entre 1974 y 2000”, en Estudios del Trabajo, ASET, Primer Semestre 2003.
KISH, L. (1995): “Survey Sampling”, New York, Wiley.
KISH, L. (1972): “Muestreo de encuestas”, Trillas, México.
MAURIZIO, R. (2001), “Demanda de trabajo, sobreeducación y distribución del ingreso”, Ponencia presentada al Quinto Congreso Nacional de Estudios del Trabajo, ASET, Buenos Aires.
PÉREZ, P. (2005): “Sobreeducación en el mercado de trabajo Argentino en un período de desempleo masivo (1995-2003)”, ponencia presentada en 7mo Congreso Nacional de Estudios del Trabajo, ASET.
SALAS, M. (2005): “El fenómeno de sobrecalificación: calificaciones y competencias”, ponencia presentada en 7mo Congreso Nacional de Estudios del Trabajo, ASET.
WAISGRAIS, S. (2005): “Determinantes de la sobreeducación de los jóvenes en el mercado laboral Argentino”, ponencia presentada en 7mo Congreso Nacional de Estudios del Trabajo, ASET.
Documentos Metodológicos:
Encuesta permanente de hogares. Base usuaria ampliada de EPH (BUA). Diferentes años.
RAESTA 3 - Año 3 (2016)
Presentación
Artículos
Desempeño de las PyME industriales argentinas, 2005-2011: Medición de eficiencia en la producción a través de un enfoque no-paramétrico. +Laura MastroscelloAnálisis multivariado aplicado a la generación de escenarios complejos en torno a concepciones de sexualidad y género en alumnos de escuelas medias. +Sebastián Ezequiel SustasLucas KlobovsLiliana Pascual“El análisis de redes sociales como herramienta para focalizar la intervención en entornos rurales a través de políticas públicas. +Nicolás Vladimir Chuchco / Cintia Noelia Díaz / María Leonor Pérez BrunoNicolás Sacco
RAESTA 2 - Año 2 (2015)
Editorial
Artículos
Bruno De SantisConstrucción de un índice del nivel socioeconómico del hogar urbano en la República Argentina mediante el análisis de correspondencia múltiple y escalamiento óptimo. +María Fernanda Artola / Iván Redini BlumenthalOrientaciones de futuro laboral y educativo de estudiantes secundarios. Análisis multivariado en un diseño muestral complejo. +Rosario AustralMarcelo Bergman / Diego Masello / Christian Arias / Guadalupe Peralta AgüeroUn ejemplo de diseño cuasi experimental: uso de la regresión logística binaria en la construcción de un grupo de comparación para la evaluación de impacto de un programa social. +Horacio ChitarroniMetodología estadística para la estimación de las superficies sembradas con cultivos extensivos - método de segmentos aleatorios. +Norberto V. Rodríguez / Julieta Mirensky
RAESTA 1 - Año 1 (2014)
Editorial
Artículos
La pérdida de valor de las credenciales educativas en el mercado de trabajo Argentino 1995-2001. Una respuesta desde los métodos estadísticos. +Florencia SourrouilleLos docentes en la Encuesta Permanente de Hogares. Notas metodológicas para su identificación y estudio. +Leandro BottinelliEspecificación del modelo, datos faltantes y casos atípicos: la “trastienda” de una investigación basada en el análisis de la varianza. +Luisa IñigoAna María Capuano