La pérdida de valor de las credenciales educativas en el mercado de trabajo Argentino 1995-2001. Una respuesta desde los métodos estadísticos.
En este trabajo se sostiene que durante la segunda mitad de la década de 1990 se desarrolló un proceso de pérdida de valor de las credenciales educativas de los trabajadores con nivel de estudios secundario completo o mayor. Como a su vez en el período se incrementó la desigualdad salarial se sostiene que lo que se observa es un fenómeno de dos aristas: de devaluación educativa y segmentación del mercado de trabajo. Para realizar estas afirmaciones se utilizan regresiones lineales múltiples para el cálculo de premios salariales. Dado que la fuente utilizada es una muestra y el universo es pequeño se utilizan pooles de datos para ampliar la cantidad de muestra disponible y mejorar las estimaciones. Se desarrolla una metodología cuyo objetivo es poder decidir desde el punto de vista estadístico si los pooles de datos pueden ser utilizados o no en cada problema de trabajo y como trabajar con ellos, y así poder utilizar los recursos disponibles bajo el control de métodos estadísticos.
Los docentes en la Encuesta Permanente de Hogares. Notas metodológicas para su identificación y estudio.
El estudio de los docentes como colectivo laboral en Argentina puede ser realizado con precisión a partir de los Censos Nacionales de Docentes. Estas fuentes de información son específicas del sector educativo y, por lo tanto, las más idóneas para la caracterización detallada de los cargos, horas, funciones, trayectorias y formación de los docentes. Sin embargo, sus principales limitaciones son la periodicidad decenal y las dificultades para comparar a los docentes con otros grupos laborales. La Encuesta Permanente de Hogares, fuente diseñada para caracterizar y monitorear la inserción laboral de la población, permite suplir las limitaciones mencionadas en el estudio de los ocupados en las actividades de enseñanza. Sin embargo, tiene ciertas características y limitaciones que resultan importantes tener en cuenta al utilizarla para estudiar el colectivo docente. Este artículo analiza la fuente en cuanto sus potencialidades para el estudio de este grupo laboral. Concluye que es consistente para el estudio de la evolución del empleo docente.
Especificación del modelo, datos faltantes y casos atípicos: la “trastienda” de una investigación basada en el análisis de la varianza.
El artículo está centrado en la discusión de aspectos metodológicos de la investigación de tesis de la autora. En el campo de los estudios sobre la distribución personal del ingreso y los mercados de trabajo resulta habitual el análisis de la regresión del ingreso personal contra diversos atributos de los perceptores y sus ocupaciones. Este análisis tiene por requisito la resolución de cuestiones referidas a: la definición del modelo en que estará basado, el tratamiento que se dará a los casos sin información y los procedimientos mediante los que se evaluará y, eventualmente, corregirá la influencia de los casos extremos sobre los parámetros estimados. El artículo refiere qué decisiones fueron tomadas en la investigación a este respecto, fundamentando las razones y describiendo su impacto sobre los resultados obtenidos.
¿Qué son los Indicadores? Perspectivas y usos diferentes.
El presente artículo tiene como objetivo presentar las diferentes perspectivas y usos de los indicadores, por un lado, desde las ciencias sociales y por otro desde lo que se denominó “Movimiento de Indicadores Sociales”. En términos generales, el uso de los indicadores ha sido utilizado desde el enfoque de las ciencias sociales para medir empíricamente conceptos teóricos que permitan el abordaje empírico a los fenómenos sociales. Sin embargo, los indicadores son también utilizados desde una perspectiva más pragmática, principalmente por los organismos de estadística y organismos internacionales. A través del artículo se presentan los diferentes recorridos realizados por las perspectivas mencionadas. En la primera parte se describe la medición empírica de conceptos a través de indicadores en los principales referentes de las ciencias sociales. En la segunda parte se describe el contexto de surgimiento y el desarrollo de lo que se denominó “Movimiento de Indicadores Sociales” como otra forma de aproximación al estudio de la realidad social a través de indicadores. En la tercera se problematiza las diferencias de ambas perspectivas en cuanto a los objetivos y el método que utilizan y se presenta como conclusión la importancia de vincular ambas perspectivas.
Aportes al estudio de la opinión pública en las elecciones presidenciales 2007 en Argentina.
El presente trabajo intenta explorar la creciente importancia que los estudios de opinión pública han comenzado a tener durante las últimas décadas. En este sentido, se busca brindar un aporte a la investigación dentro de una actividad que siempre ha estado más bien alejada del ámbito académico, en especial en los estudios relacionados con los procesos electorales. Asimismo, el trabajo intenta develar la notable injerencia que los medios de comunicación tienen en los procesos electorales de los últimos años, demostrándose que se trata de una tendencia que va tomando cada vez más impulso. Finalmente, se analizaran cuestiones que resultan un aporte para diagnosticar los cambios en las percepciones de la ciudadanía durante la etapa previa y posterior a una elección.
Construcción de un índice del nivel socioeconómico del hogar urbano en la República Argentina mediante el análisis de correspondencia múltiple y escalamiento óptimo.
El trabajo presenta la construcción de un índice que tiene como finalidad asignar a cada hogar urbano de la República Argentina un nivel socioeconómico. Se piensa al índice como una variable latente (no observable) y se aplica el análisis de correspondencia múltiple, método exploratorio de estadística multivariada, para obtener los ponderadores (pesos) de las modalidades de las doce variables seleccionadas.
El índice se compone de variables relativas a las características de la vivienda, la condición laboral y educativa del jefe de hogar y del cónyuge. La metodología se aplica a la Encuesta Nacional de Gasto de los Hogares 2012/2013 (Instituto Nacional de Estadísticas y Censos). Una vez estimados los puntajes de la variable latente para los hogares urbanos, se establecen los quintiles socioeconómicos y se asigna a cada hogar un quintil. Finalmente, se analizan las características de cada uno de los quintiles obtenidos y se indican las fortalezas y limitaciones de la metodología.
Orientaciones de futuro laboral y educativo de estudiantes secundarios. Análisis multivariado en un diseño muestral complejo.
En este artículo se analizan las orientaciones de futuro laboral y educativo de los estudiantes que a fines de 2008 cursaban el último año de estudio en las escuelas estatales de la Ciudad Autónoma de Buenos Aires. En primer lugar, se describen las orientaciones de futuro hallándose una prevalencia de proyectos educativo-laborales entre los estudiantes y una anticipación de obstáculos que resulta más pronunciada en el plano laboral que en el educativo. Luego, mediante un análisis de regresión logística multivariada, se compara la influencia relativa de distintos atributos sociales, escolares, biográficos y de la oferta educativa sobre los objetivos de tipo profesional. Entre los principales resultados se halla que las diferencias de género muestran contundencia en la priorización de un objetivo profesional. La modalidad del plan de estudios también emerge como un aspecto clave en los horizontes de futuro, observándose un hiato entre la formación bachiller-comercial y la técnica, donde prevalecen expectativas de inserción laboral directa luego del egreso. Otro hallazgo es que en el plano educativo los horizontes de profesionalización adquieren una difusión más amplia e independiente del origen social educacional, como reflejo de un contexto donde están dadas ciertas condiciones para el acceso masivo a la educación superior. Por otra parte, en el trabajo se enfatiza la importancia de considerar la complejidad del diseño muestral en la instancia de análisis de los datos. Para ello se comparan los resultados obtenidos con estimadores que consideran la complejidad de diseño muestral con otros “naive”, reflexionando acerca de las implicancias epistemológicas que esto conlleva en la puesta a prueba de hipótesis en el análisis bivariado y multivariado.
“Condiciones de socialización, entorno y trayectoria asociados a la reincidencia en el delito”.
En la actualidad el delito y la punición son analizados desde diferentes enfoques, ya que además de estar en crisis son temas a los cuales se les busca encontrar respuestas y soluciones. Es sabido entre los expertos que estudian estos tópicos que dentro de las cárceles la población es mayoritariamente joven, con bajos niveles de educación y provenientes de clases socioeconómicas medias/bajas y bajas, caracterizadas, entre otras cosas, por los bajos niveles de ingreso.
Teniendo en cuenta estas características podría pensarse que la vinculación explicativa de una conducta delictiva está dada por la asociación entre la condición de pobreza de un hogar y/o de sus integrantes y las probabilidades de comisión de delitos y la reincidencia en los mismos. Sin embargo, en este documento proponemos la existencia de una relación mucho más compleja. Por lo tanto, cabe preguntarse en relación al delito y a la reincidencia en el mismo, ¿qué tan asociados están esos factores a quienes incurren nuevamente en una conducta delictiva y al nivel de violencia al momento de perpetrar un delito?, finalmente, ¿qué factores son estos?
Para responder a estas preguntas se realizó un modelo de análisis multivariado basado en una regresión logística, en el cual se incorporaron variables relacionadas con los entornos o contextos de socialización temprana de los sujetos así como la trayectoria en instituciones como los institutos de menores. Los datos utilizados pertenecen a la Encuesta a Población en Reclusión de 2013, en la cual para Argentina se aplicaron más de mil encuestas personales a presos condenados por la justicia federal y ordinaria de la Capital así como por la justicia de la Provincia de Buenos Aires. Cabe destacar, además, que este fue un estudio que abarcó un conjunto de otros cinco países de la región: Brasil, Chile, El Salvador, México y Perú.
Un ejemplo de diseño cuasi experimental: uso de la regresión logística binaria en la construcción de un grupo de comparación para la evaluación de impacto de un programa social.
Este artículo trata acerca del empleo de la regresión logística binaria para la construcción de un grupo de comparación útil para la evaluación de impacto de un programa social. Se basa en una experiencia de aplicación real de tal procedimiento.
En la primera parte se aborda brevemente la problemática que plantea la implementación de diseños puramente experimentales en el caso de la evaluación de políticas públicas de contenido social y la alternativa de emplear modelos cuasi experimentales con un grupo de comparación construido estadísticamente. También se ponen en consideración algunas cuestiones inherentes a los diseños con doble medición, al tiempo que se abordan las dificultades que plantea la frecuente ausencia de una línea de base en el caso de los programas sociales. Asimismo, se explicitan los requisitos que debieran cumplimentar los grupos de comparación construidos mediante modelación estadística.
La segunda parte se refiere a las características del procedimiento estadístico empleado (la regresión logística binaria) y su utilidad específica para la obtención de grupos de comparación, con las limitaciones e inconvenientes que plantea, las alternativas posibles para sortearlos y los recaudos a adoptar. Finalmente, en la última parte se exponen los resultados provenientes del ejemplo de aplicación de este procedimiento conjuntamente con la interpretación de los mismos.
METODOLOGIA ESTADISTICA PARA LA ESTIMACION DE LAS SUPERFICIES SEMBRADAS CON CULTIVOS EXTENSIVOS - METODO DE SEGMENTOS ALEATORIOS.
El conocimiento de la superficie sembrada con cultivos extensivos es de relevancia estratégica para el país y necesita ser estimada en forma objetiva dos veces al año para las principales Provincias Argentinas. El método aquí propuesto es el de observar –con el significado literal de la palabra- una muestra de segmentos que se definen, como relativamente pequeñas áreas que toman la forma de polígonos rectangulares, sin consultar a los dueños de las tierras, a los productores ni a ninguna persona relacionada con las explotaciones que contiene el segmento.
La selección original es de puntos aleatorios dentro de estratos de uso homogéneo del suelo, que luego se los transforma en segmentos. Es obvio que gran parte de los puntos caerán en lugares que no se pueden acceder con un vehículo y para poder llevar a cabo la observación es necesario trasladar el punto hasta el camino más próximo y allí conformar el segmento. Desde el punto de vista de la teoría del muestreo se reconoce que el procedimiento de trasladar origina un sesgo el cual es un error no debido al muestreo.
La contrapartida es que el método tiene importantes ganancias, entre ellas: a) muy alta confiabilidad de los datos por provenir de observaciones “in situ” hechas por expertos, b) no hay error en la medida de las superficies por utilizar tecnología satelital, c) una vez definido el segmento el Sistema de Posicionamiento Global (GPS) permite controlar el operativo y anula el error de ubicación de los segmentos en futuros operativos, d) las muestras son altamente comparables en el tiempo, e) los resultados se obtienen en breve tiempo, en general no más de tres meses, f) reducción notable del presupuesto al no existir revisitas.
El método incorpora nuevas tecnologías, entre ellas: imágenes satelitales, Sistemas de Información Geográfica (GIS), el GPS, el uso del Índice de Vegetación de Diferencia Normalizada (NDVI), programas de procesamiento de la información y protocolos estrictos de procedimientos.
Desempeño de las PyME industriales argentinas, 2005-2011: Medición de eficiencia en la producción a través de un enfoque no-paramétrico.
Este trabajo mide la eficiencia en la producción de las PyME industriales argentinas a partir de la productividad total de los factores, para el período 2005-2011, utilizando datos a nivel empresa, y aplicando el enfoque Análisis Envolvente de Datos (DEA por sus siglas en inglés) basado en el trabajo de Farrell (1957) y las extensiones introducidas por Charnes et al (1978) y Banker et al (1984). Se busca generar un aporte desde el punto de vista metodológico, como antecedente en lo referido a cómo puede medirse la eficiencia de las PyME industriales argentinas en base a información estadística disponible, y explorar cuáles son los factores determinantes de la misma, ya que hasta el momento hay un vacío de información en este sentido. A partir de esto, se explora la asociación de este nivel de eficiencia con factores exógenos a las empresas o internos a las mismas como potenciales determinantes del mismo. Se encuentra que las PyME localizadas en las regiones del país de mayor desarrollo relativo y concentración de la actividad económica tienen un nivel de eficiencia en promedio mayor al resto. Mientras que, sorprendentemente, no hay evidencia suficiente para suponer que el sector de actividad de pertenencia está relacionado con el nivel de eficiencia en la producción. Por otro lado, contrariamente a lo esperado, las empresas más grandes, que exportan, y que solicitan y obtienen créditos bancarios, registran en promedio menores niveles de eficiencia que el resto, aunque esto podría explicarse por el hecho de que estas firmas están más capitalizadas, lo que, al incrementar su dotación del factor de producción capital, impacta negativamente en su eficiencia técnica de producción.
Análisis multivariado aplicado a la generación de escenarios complejos en torno a concepciones de sexualidad y género en alumnos de escuelas medias.
En el presente artículo se exponen aspectos analíticos y metodológicos de la aplicación de diversas técnicas de análisis de datos multivariados empleadas en una investigación sobre salud sexual y reproductiva y educación sexual. Se propone la categoría de escenarios complejos como construcción analítica que permite poner en vinculación concepciones, creencias y actitudes sobre sexualidad, diversidad sexual, género y aborto en base a un relevamiento por encuestas estructuradas en mujeres y varones adolescentes escolarizados en el nivel medio de Argentina realizado durante el segundo semestre del 2012. Dicho relevamiento tuvo como propósito principal indagar y explorar las formas en que determinadas concepciones sobre la sexualidad y el género de los alumnos se vinculan con modelos de educación sexual, las temáticas priorizadas en dichos abordajes, las formas en que se establecen los vínculos con docentes y adultos, los vínculos afectivos intrageneracionales, y las instancias de subjetivación juvenil. Se aplicaron una serie de técnicas estadísticas multivariadas: análisis de componentes principales, análisis de cluster por el método de K-medias y, fundamentalmente, el análisis de correspondencias múltiples para la generación de los escenarios complejos.
Las elecciones a Presidente de Argentina en 2011 y 2015.
La elección a Presidente en Argentina de 2011 tuvo como ganadora a la candidata por el Frente para la Victoria Cristina Kirchner con una amplia diferencia respecto al segundo. El triunfo de la candidata tiene diferentes explicaciones causales desde el punto de vista de las motivaciones del voto por parte del electorado. A través de la presente investigación se intenta identificar las variables condicionantes y jerarquizarlas. Las características socio demográficas del ciudadano no tienen la influencia de otros momentos. En cambio, variables relacionadas con la gestión, el posicionamiento de los candidatos y el vínculo entre Néstor Kirchner y su esposa adquieren mayor protagonismo como condicionantes del voto.
El triunfo de Mauricio Macri en la elección presidencial de 2015 también tiene sus explicaciones causales. Sin entrar en la profundidad de la elección de 2011, se encontraron aspectos ideológicos y vinculados al consumo como elementos motivadores del voto.
Las estadísticas educativas y los desafíos futuros: un sistema de información por alumno.
Este trabajo analiza tanto los antecedentes como las características actuales del sistema de información estadística del sistema educativo argentino. Se plantea también el camino futuro de este sistema, teniendo en cuenta los cambios tecnológicos que tuvieron lugar en nuestro país en los últimos años.
Actualmente, el sistema nacional de información educativa está basado, principalmente, en el Relevamiento Anual, operativo censal que recoge con un corte anual la información consolidada a nivel nacional sobre las principales variables del sistema educativo, exceptuando las universidades. Este sistema garantiza una información homogénea y comparable para todo el ámbito nacional.En la actualidad el sistema de información educativa enfrenta nuevos desafíos producto de un sistema educativo complejo y en constante transformación. Además, el Relevamiento Anual presenta varias limitaciones y solo permite analizar en forma parcial los nudos críticos del sistema educativo. Para paliar estas limitaciones, durante los años 2013 y 2015, se desarrolló un Sistema Integral de Información Digital Educativa —SInIDE—, basado en información nominal de los alumnos. Este nuevo sistema articula y compatibiliza los requerimientos de información de las distintas instancias de gestión en los niveles nacional y jurisdiccional y permite que las instituciones educativas desarrollen a través de este sistema sus propios procesos administrativos y pedagógicos. Su potencialidad radica en la posibilidad de acelerar todos los procesos y de recoger datos adicionales para diagnosticar el funcionamiento del sistema educativo y las trayectorias educativas de los alumnos, tanto a nivel de los establecimientos como a nivel provincial o nacional. Además, permite la construcción de nuevos indicadores para evaluar la situación del sistema educativo en todo el país, fortaleciendo las políticas que se llevan a cabo en el marco de la Ley de Educación Nacional.
El análisis de redes sociales como herramienta para focalizar la intervención en entornos rurales a través de políticas públicas.
Este trabajo muestra los resultados mediante la aplicación de un instrumento de recolección de datos reticulares para un estudio de línea de base y evaluación de políticas públicas en entornos rurales, a fin de describir, medir y comparar las formas de las asociaciones entre los agentes involucrados de dos cooperativas.
Los objetivos de la ponencia radican en describir y caracterizar las redes de asociaciones de pequeños productores rurales en un contexto social delimitado, y evaluar la viabilidad de complementar los análisis estadísticos cuantitativos tradicionales con la metodología del análisis de redes sociocéntricas, para focalizar las formas de intervención y detectar asociaciones latentes y potenciales.
Los resultados obtenidos al aplicar este instrumento en dos agrupaciones de pequeños productores rurales del Noroeste argentino, beneficiarios de un programa social en el año 2014, muestran dos grafos multiplexados diferenciados. Mientras que en la primera red la forma de las asociaciones para movilizar recursos estratégicos se encuentra restringida por la autoridad de los referentes de la organización, en la segunda se observa una distribución más equitativa y menos autoritaria de los vínculos, así como una intermediación menos centralizada.
Se concluye que esta metodología ha sido adecuada para describir las fuerza, dirección y circulación de las relaciones entre los nodos de las agrupaciones relevadas, así como la existencia de asociaciones potenciales que no sean efectivizado. De esta forma la toma de decisiones se ve beneficiada al disponer de información específica, que permite detectar la necesidad de fortalecer vínculos, así como la posibilidad de identificar nodos y subgrupos que centralizan la intermediación y los recursos o que pueden desarrollar una mejor circulación de los mismos a causa de sus posiciones estratégicas en las redes.
Las clases sociales según los censos de población de 1991 y 2001.
El artículo presenta una metodología para la reconstrucción de las series del Nomenclador de Condición Socio-Ocupacional y el esquema de clases de Torrado a lo largo del período 1980-2001, durante el cual los cambios en los sistemas clasificatorios de las variables involucradas en su construcción presentaron importantes cambios. Se utilizaron los datos secundarios del estudio “Estructura Social Argentina” del Consejo Federal de Inversiones para el censo de 1980 y los datos publicados por el Instituto Nacional de Estadística y Censos de los censos de población de 1991 y 2001, para el Total del País.
La investigación aborda tanto las cuestiones metodológicas enfrentadas a la realidad de la oferta estadística en Argentina así como también aspectos teóricos sobre la temática de la estructura social. Se realiza un detallado análisis de las fuentes existentes que permiten la construcción de series lo más homogéneas posibles en términos metodológicos con el objetivo de que muestren los cambios de la estructura social entre fines de los cuarenta y la actualidad. Se analizan también los resultados alcanzados. En lo que hace a este aspecto, sin embargo, la profundidad de la indagación es menor.
El aporte permite continuar y armonizar, con las dificultades y advertencias metodológicas que implica, los trabajos de Germani (1955) y Torrado (1992) y el análisis de la estructura social Argentina según datos secundarios cuantitativos.
Palabras clave: Condición Socio-Ocupacional; clases sociales; censos de población; estructura social argentina; mercado de trabajo; ocupación; empleo.
RAESTA 2 - año 2 (2015)
Artículos
Un ejemplo de diseño cuasi experimental: uso de la regresión logística binaria en la construcción de un grupo de comparación para la evaluación de impacto de un programa social.
Una aproximación explicativa utilizando un modelo multivariado de análisis
Horacio Chitarroni1

Introducción
Este artículo trata acerca del empleo de la regresión logística binaria para la construcción de un grupo de comparación útil para la evaluación de impacto de un programa social. Se basa en una experiencia de aplicación real de tal procedimiento llevada a cabo por el autor.
En la primera parte se aborda brevemente la problemática que plantea la implementación de diseños puramente experimentales en el caso de la evaluación de políticas públicas de contenido social y la alternativa de emplear modelos cuasi experimentales con un grupo de comparación construido estadísticamente. También se ponen en consideración algunas cuestiones inherentes a los diseños con doble medición, al tiempo que se abordan las dificultades que plantea la frecuente ausencia de una línea de base en el caso de los programas sociales. Asimismo, se explicitan los requisitos que debieran cumplimentar los grupos de comparación construidos mediante modelación estadística.
La segunda parte se refiere a las características del procedimiento estadístico empleado (la regresión logística binaria) y su utilidad específica para la obtención de grupos de comparación, con las limitaciones e inconvenientes que plantea, las alternativas posibles para sortearlos y los recaudos a adoptar.
En la tercera parte se exponen los resultados provenientes de un ejemplo de aplicación conjuntamente con la interpretación de los mismos. Por fin, se enuncian unas breves conclusiones.
1. Las evaluaciones de impacto y los diseños experimentales
Tal como lo señala Baker (2000: 2) “En general se considera que los diseños experimentales, conocidos también como aleatorización, son las metodologías de evaluación más sólidas”.
La situación ideal del diseño experimental, tal como la describen habitualmente los textos, es aquella en que el grupo de control es una muestra extraída de la misma población de la cual proviene el grupo de tratamiento. Es más: la idea es que ambos grupos resulten de la partición al azar de una misma muestra, antes de que comience a operar el estímulo (Heirinch, Maffioli y Vázquez, 2010). Cuando ello es así, el azar nos otorga “garantías” de que ambos grupos no diferirán significativamente en nada. Están controlados los factores conocidos y también los desconocidos por el investigador. Tal como lo ha dicho Blalock (1971: 29):
En la práctica, confiamos en que las leyes de probabilidad produzcan distribuciones similares de todos los factores personales que intervienen en el experimento (…) La principal ventaja de la aleatorización es que toma en cuenta numerosos factores en forma simultánea sin que nos veamos obligados a saber cuáles son.
En ocasiones, también se recurre al sistema denominado matching o apareamiento: en este caso pueden formarse, a partir de la muestra original, pares de casos que se asemejen en los valores de un conjunto de variables que se consideren cruciales en la investigación. Por ejemplo, sujetos de igual edad, sexo, nivel educativo y situación ocupacional. Hecho esto, cada miembro de cada par así conformado sería adjudicado en forma aleatoria al grupo experimental o al grupo de control. El propósito es que cada integrante del grupo experimental tenga un gemelo en el grupo de control. Este procedimiento es, sin embargo, trabajoso y está limitado a muestras de tamaño reducido, Por lo demás, no garantiza igualdad en todos los posibles factores intervinientes, sino tan solo en aquellos que han sido tenidos en cuenta en el pareo.
Obviamente, la primera situación mencionada es poco frecuente en la realidad. Podría lograrse en la prueba de un tratamiento nuevo, si se dispusiera de un buen número de pacientes con una similar dolencia y se los dividiera aleatoriamente: algunos recibirían un tratamiento tradicional (o bien ningún tratamiento) y otros la nueva droga. Claro que esto no podría hacerse legítimamente si conllevara algún tipo de riesgos para los pacientes. En el caso de las políticas sociales se agregan dificultades adicionales, tal como lo señala Baker (2000: 2):
Aunque los diseños experimentales se consideran el método óptimo para estimar el impacto de un proyecto, en la práctica conllevan varios problemas. Primero, la aleatorización podría ser poco ética debido a la negación de beneficios o servicios a miembros de la población de por sí calificados para el estudio. Como un ejemplo extremo se podría citar la negación de tratamiento médico que podría salvar la vida de algunos miembros de la población.
Segundo, puede ser políticamente difícil proporcionar una intervención a un grupo y no a otro. Tercero, el alcance del programa podría significar que no hubiera grupos sin tratamiento, como en el caso de un proyecto o cambio de política de amplio alcance.
Una alternativa sería apelar a algún criterio justificable de priorización: los más necesitados o vulnerables –en el supuesto de que ello pudiera ranquearse– o bien los que reunieran más de las condiciones de admisibilidad si éstas fueran varias. Pero si usáramos un criterio de este segundo tipo, ya quedaría vulnerada la igualación inicial: habría un sesgo pues los que entraran más tarde serían “menos algo” que los priorizados.
Supongamos que se eligiera a quienes aunque reúnen las condiciones deciden por su cuenta no postularse: aquí habría un sesgo de autoselección. Algo tendrán de diferente –una condición desconocida y no visible– quienes se autoexcluyen. Tampoco esto funcionaría aceptablemente.
Eventualmente sería algo más admisible tomar a aquellos que fueron rechazados por alguna razón de orden administrativo, tal que no pudiera suponerse que establece diferencias, es decir, no asociable a otras condiciones. Ello no resulta sin embargo tan fácil: si alguien no tiene –por ejemplo– documentación en regla porque es extranjero o hijo de extranjeros, ya eso mismo establece diferencias. Se asocia a condiciones que podrían ser objeto de la evaluación o interactúa con ellas. Un niño carente de documentación no podría recibir la AUH2, pero tampoco podría ir a la escuela.
Algunas de estas alternativas son, sin embargo, empleadas a veces en diseños cuasi experimentales, menos rigurosos, a falta de otras mejores.
Medición antes/después e interacciones
En algunas ocasiones en que no se puede garantizar la igualdad inicial por procedimientos de azar, es posible en cambio acudir a una medición previa de la variable dependiente en ambos grupos. Esta primera medición permite tener la certeza de que los grupos no difieren significativamente en dicha variable3.
Luego de introducido el estímulo sobre uno de los grupos, es posible realizar una segunda medición de la variable dependiente en ambos. No es preciso que cada grupo mantenga el valor inicial: puede haber un “efecto maduración”, consistente en cambios operados debido a la influencia de otros factores o al simple transcurso del tiempo.
En estos casos se emplea el método denominado “diferencia de diferencias”: se establece la diferencia entre la medición inicial y la final en cada uno de los grupos. Tal vez ambos cambiaron, pero si la variable independiente produjo lo cambios, el grupo que recibió tratamiento debiera haberla variado más: mostraría, pues, una diferencia mayor entre ambos momentos de medición. Y esta “diferencia de diferencias” se atribuiría a la acción del estímulo.
Podría ocurrir, sin embargo, que haya un efecto de la primera medición que se combine con el estímulo, reforzándolo o atenuándolo, en una suerte de efecto interacción. Discriminar estas interacciones requiere la formación de cuatro grupos aleatorizados o igualados, si el factor experimental es dicotómico, en tanto que el número aumenta a 2*N si hay N valores del factor experimental (Campbell y Stanley, 1995).

Así, el primer grupo experimental (E) recibiría el estímulo y sería medido en ambas oportunidades, en tanto que el segundo grupo experimental (E’) solo sería sometido a la medición final. Otro tanto se haría con los grupos de control (C y C’). La comparación de la variación en los cuatro grupos.
Diseños ex post
Pero hay un segundo problema. Muy frecuentemente la formulación de las políticas no contempla desde su origen una instancia de evaluación: la necesidad de hacerlo surge a posteriori, cuando ya llevan cierto tiempo de ejecución. Cuando las acciones cuyo impacto se desea evaluar ya se han estado ejecutando y han causado –o no– sus efectos.
En estas evaluaciones ex post, sería preciso desplazarse hacia atrás en la búsqueda del grupo de control. Y la medición inicial está irremediablemente ausente, puesto que el fenómeno cuyo impacto deseamos medir o comprobar ya ha ocurrido.
¿Qué se puede hacer en estas situaciones en que las condiciones ideales del experimento están ausentes o no son reproducibles? No queda otra alternativa que procurar aproximaciones a ellas.
Cuando estas son las condiciones contamos, inevitablemente, con una única medición llevada a cabo después de cierto tiempo “bajo programa”. Desconocemos, en rigor, la situación inicial de los beneficiarios: no hay una línea de base. Lo cual no sería tan grave si contáramos con un grupo de control proveniente de la misma población que los beneficiarios: rezagados que todavía no recibieron ningún beneficio pero que se postularon junto con los actuales beneficiarios. Y a condición de que el criterio de priorización hubiese sido aleatorio, porque entonces, cabría suponer la igualdad inicial, que haría innecesaria la primera medición. Pero supongamos que no lo tenemos: por ejemplo porque todos entraron ya al programa.
Es en estos casos cuando resulta posible apelar a la conformación de un grupo de comparación ex post y proveniente de una población que no es la de los beneficiarios, mediante un procedimiento estadístico. Se trata de establecer la “probabilidad de participar” o propensity score (Rosembaun y Rubin, 1983; 1985; Caliendo y Copeinig, 2005; Heirinch, Maffioli y Vázquez, 2010). El propósito estriba en contar con un grupo de no participantes asimilable a los participantes, al punto que se pueda asumir la igualdad inicial. El supuesto que hará falta asumir es que si ambos grupos hubieran sido objeto de una medición previa no hubieran presentado diferencias apreciables, por pertenecer ambos a la misma población. Por lo tanto, si tales diferencias se manifiestan en la medición ex post, podremos atribuirlas a las acciones del programa.
En rigor, se trata de un sucedáneo cuasi experimental de la situación ideal, pero de muy frecuente uso en las ciencias sociales (y especialmente en la evaluación de políticas) puesto que las condiciones del diseño experimental puro raramente son reproducibles.
Entre las técnicas de diseño cuasi experimental en general se considera que las técnicas de comparación pareada son la alternativa subóptima al diseño experimental. Gran parte de la literatura sobre metodologías de evaluación se centra en el uso de este tipo de evaluaciones, lo que indica el frecuente uso de las comparaciones pareadas y los numerosos desafíos que plantea el contar con grupos de comparación poco adecuados. En los últimos años se han producido significativos avances en las técnicas de correspondencia de puntuación de la propensión (…) Se pueden emplear métodos cuasi experimentales (no aleatorios) para realizar una evaluación cuando es imposible crear grupos de tratamiento y de comparación a través de un diseño experimental. Estas técnicas generan grupos de comparación que se asemejan al grupo de tratamiento, al menos en las características observadas (…) Cuando se usan estas técnicas, los grupos de tratamiento y de comparación por lo general se seleccionan después de la intervención usando métodos no aleatorios. Por lo tanto, se deben aplicar controles estadísticos para abordar las diferencias entre los grupos de tratamiento y de comparación y emplear técnicas de pareo sofisticadas para crear un grupo de comparación que sea lo más similar posible al grupo de tratamiento. En algunos casos también se selecciona un grupo de comparación antes del tratamiento, aunque la selección no es aleatoria (Baker, 2000: 3 a 5).
Los requisitos
La literatura referida a la selección de grupos de comparación basados en la “propensión a participar”, usualmente plantea requisitos bastante estrictos. En rigor los datos de beneficiarios y no beneficiarios debieran provenir de la misma fuente: una encuesta común. O, al menos, una encuesta aplicada a los beneficiarios paralela en el tiempo a otra encuesta domiciliaria realizada en la misma área geográfica y con el mismo instrumento de recolección.
Inclusive se ha enfatizado la conveniencia de que los encuestadores sean los mismos o al menos pueda garantizarse que recibieron una instrucción análoga antes de abocarse al trabajo de campo. Todo ello, encaminado a asegurar la fiabilidad y comparabilidad de los datos, evitando la introducción de sesgos. O al menos, garantizando que de haber sesgos, estos no se manifestarían de modo disímil entre uno y otro grupo.
¿Qué tipo de sesgos podrían producirse?: por ejemplo, que los sectores que residen en cierto tipo de barrios estén subrepresentados en la muestra. Las villas de emergencia, por caso, son lugares de difícil y riesgoso acceso para encuestadores, si ellos no cuentan con algún contacto interno que franquee el ingreso. Y generalmente la proporción de hogares residentes en villas en las encuestas de hogares (por caso la EPH4 ) son inferiores a las que revelan los censos. Ocurre otro tanto, en el extremo opuesto, con la población que habita barrios cerrados, a los que no pueden acceder fácilmente los encuestadores.
Sin embargo, si ese sesgo de selección afectara por igual a ambas muestras (GT y GC), aunque no se lo pudiese evitar no afectaría en demasía la comparación. Por ejemplo, que en ambos grupos estuvieran subrepresentados los sujetos pertenecientes a los estratos más altos: si eso sucediera en igual medida en los hogares del grupo de tratamiento y del grupo de comparación, no ocasionaría dificultades de gran importancia5.
Por ejemplo, en la Ciudad Autónoma de Buenos Aires se realizaba un relevamiento de los beneficiarios del programa Ciudadanía Porteña6 –seleccionados al azar del padrón– con el mismo instrumento y en el momento en que estaba en campo la Encuesta Anual de Hogares de la Ciudad. Y con los mismos equipos de la Dirección de Estadísticas y Censos. Y resultaba posible “pegar” una encuesta a la otra ya que ambas contendrán los mismos campos.
No obstante, sería muy importante que la encuesta general identifique mediante una pregunta a los beneficiarios del programa a evaluar, de manera de no correr el riesgo de incluirlos indebidamente –por desconocer que lo son– en el grupo de comparación, que resultaría así severamente contaminado. Pues algunos miembros del mismo podrían experimentar cambios imputables al programa, estrechando las “diferencias”. Eso conduciría a subestimar los efectos de la exposición al programa.
En el caso de la encuesta de hogares de la Ciudad Autónoma de Buenos Aires sucedía efectivamente así. El programa estaba lo suficientemente extendido como para que la encuesta captara beneficiarios en su muestra. En la encuesta de 2011, por caso, había en la muestra 357 casos de hogares beneficiarios: casi un 6% del total. Estos hogares debieran ser excluidos del grupo de control.
2. El procedimiento
Una vez que se cuenta con una base en la que los beneficiarios del programa “cohabitan” con el resto de la población, la tarea será conformar el grupo de comparación proveniente de esta última mediante la estimación de la “probabilidad de participar” (del programa).
En la base hay hogares provenientes del padrón de beneficiarios del programa –los que efectivamente “participan”– y hay hogares relevados por la encuesta general que no son beneficiarios (habremos identificado y excluido deliberadamente a los hogares beneficiarios relevados por la encuesta general, si es que los hubiera).
Tendremos una variable dependiente dicotómica o binaria cuyos valores serán conocidos: ser o no ser beneficiario. La idea es emplear una herramienta estadística que permita predecir esa condición, basándose en un conjunto de características observables de los hogares, sobre las que la base de datos también cuente con información relevada de manera análoga. La regresión logística resulta un procedimiento adecuado a tales fines (Austin, 2011).
La regresión logística binaria
La regresión logística binaria es un instrumento estadístico de análisis multivariado, de uso tanto explicativo como predictivo. Resulta útil su empleo cuando se tiene una variable dependiente dicotómica (un atributo cuya ausencia o presencia hemos puntuado con los valores cero y uno, respectivamente) y un conjunto de variables predictoras o independientes, que pueden ser cuantitativas (en cuyo caso se las denomina como covariables o covariadas) o categóricas (Hosmer y Lemeshow, 2000). En este último caso, se requiere que sean transformadas en variables dummy, es decir variables simuladas.
Los propósitos del análisis consisten en:
a) Predecir la probabilidad de que a alguien le ocurra cierto “evento”. Por ejemplo: estar desempleado =1 o no estarlo = 0; ser pobre = 1 o no pobre = 0; ser beneficiario de un programa social =1 o no serlo = 0).
b) Determinar qué variables pesan más para aumentar o disminuir la probabilidad de que a alguien le suceda el evento en cuestión.
La asignación de probabilidad de ocurrencia del evento a un cierto sujeto, así como la determinación del peso de cada una de las variables dependientes en esta probabilidad, se basan en las características que presentan los sujetos a los que, efectivamente, les ocurren o no dichos sucesos.
• Por ejemplo, la regresión logística tomará en cuenta los valores que asumen en una serie de variables (edad, sexo, nivel educativo, posición en el hogar, origen migratorio, etc.) los sujetos que son efectivamente beneficiarios (B = 1) y los que no lo son (B = 0).
• En base a ello, predecirá a cada uno de los sujetos –independientemente de su estado real y actual– una determinada probabilidad de ser desocupado (es decir, de tener valor 1 en la variable dependiente) en base a un conjunto de características que podemos suponer que dan cuenta de dicha condición.
• Por ejemplo, si se tratara de un programa que transfiere ingresos a familias vulnerables y con niños. Si alguien es una jefa de hogar joven, con tres hijos pequeños, de baja educación y carente de un empleo estable cubierto por la seguridad social (aunque no sea beneficiaria) el modelo le predecirá una alta probabilidad de serlo (puesto que la proporción de beneficiarios en el grupo así definidos es alta), generando una nueva variable con esa probabilidad estimada.
• Y procederá a clasificarlo como “beneficiario esperado” en otra nueva variable, que será el resultado de la predicción.
• Y además, sopesará cuál es el peso de cada una de estas variables independientes en el aumento o la disminución de esa probabilidad.
• Por ejemplo, cuando aumenta la educación disminuirá en algo la probabilidad de ser beneficiario. En cambio, cuando el sexo pase de 0 = varón a 1 = mujer, aumentará en algo la probabilidad de serlo porque la proporción de beneficiarios es mayor entre las jóvenes mujeres es mayor que entre los jóvenes varones.
• El modelo, obviamente, estima los coeficientes de tales cambios.
• Cuanto más coincidan los estados pronosticados con los estados reales de los sujetos, mejor ajustará el modelo.
En el caso que nos ocupa, se trata de que encontremos un conjunto de variables independientes o predictoras disponibles en la base que permitan identificar adecuadamente a los hogares que efectivamente sean beneficiarios de un programa o política pública, otorgándoles una alta probabilidad de serlo.
Hemos de probar con diferentes variables hasta dar con un modelo que ajuste adecuadamente. Es decir, que prediga razonablemente la condición de los hogares beneficiarios. Que los estados pronosticados coincidan lo más posible con los reales.
Por cierto que cualquier modelo estadístico comete errores. El mejor modelo posible seguramente no identificara como tales a algunos pocos hogares beneficiarios que puedan tener un perfil atípico: por ejemplo, aun en un programa de transferencias de ingresos como Ciudadanía Porteña o en la Asignación Universal por Hijo habrá entre los beneficiarios hogares con perfiles estructurales de clase media, que sin embargo no tienen miembros ocupados en empleos formales o bien tienen bajos ingresos (o al menos sus ingresos no son comprobables). Estos hogares “engañan” al modelo y serán “rechazados” por el mismo: les pronosticará una baja probabilidad de participar y los clasificará como “no beneficiarios”. A esto se le denomina error de exclusión o error de tipo I: el modelo rechaza una hipótesis verdadera. Para que se pueda confiar en que el modelo ajusta adecuadamente, este error de exclusión debiera ser pequeño: involucrar solo a una proporción baja de los realmente beneficiarios.
Pero al revés, también el modelo debiera “rechazar” a los hogares no participantes, reconociéndolos como tales en base a sus características diferentes a las de los beneficiarios. Sin embargo, es probable –y en nuestro caso deseable– que haya entre los hogares no beneficiarios algunos que tengan unas características que los hagan parecer beneficiarios. El modelo los tomaría equivocadamente por tales y les adjudicaría una alta “probabilidad de participar”. En este caso, el estado pronosticado no coincidiría con el real. Esto es lo que se denomina el error de inclusión o error de tipo II: el modelo acepta una hipótesis falsa.
Sea bienvenido este segundo error, porque al cometerlo y mediante su predicción equivocada, el modelo habrá dado con un conjunto de hogares no beneficiarios de los que podremos suponer, en principio, que se asemejan razonablemente a los beneficiarios. ¡Buenos candidatos a integrar un grupo de comparación!
La probabilidad en la regresión logística
La función logística refleja la probabilidad del evento (por ejemplo: ser participante de un programa, ser desempleado, ser graduado universitario, etc.), expresada como Odds ratio o chances (Hair et al, 1999):
Prob participante / prob no participante = 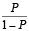 = Ez
= Ez
Donde:
E = base del logaritmo natural (2,718)
Z = a + b1X1 + b2X2 +… bnXn
Como vemos, el exponente Z es una ecuación de regresión lineal en la que:
Z = Log. PP/PNP (Prob participante/prob no participante)
a = constante del modelo (la ordenada al origen de la regresión, es decir el valor de la variable dependiente cuando todas las variables independientes asumen el valor cero)
X = variables independientes
b = pesos de cada variable independiente, que pueden ser positivos o negativos (cuando X varía en una unidad, el logaritmo del cociente PD/PND aumenta o disminuye en b unidades)
Finalmente, la probabilidad de ser participante = 1 se obtiene:
Prob(p) = Ez / (1+Ez)
Esta última es una probabilidad acotada entre 0 y 1.
Para establecer los valores de la variable dependiente en términos de una probabilidad cuyos límites son cero y uno, la regresión logística supone, en lugar de una relación lineal entre las variables –como lo es el ajuste a una recta de mínimos cuadrados ordinarios– el ajuste a una curva en forma de S. En este modelo, cuando la variable independiente asume valores bajos, la probabilidad se aproxima a cero, en tanto que así como crecen los valores de la variable independiente, esta probabilidad se incrementa a lo largo de la curva pero, a partir de cierto valor la pendiente comienza a decrecer y se estabiliza, de modo que la probabilidad se aproxima a la unidad sin excederla (Hair et al, 1999).
En vez de los mínimos cuadrados, en la regresión logística los valores de las estimaciones se establecen en base al denominado supuesto de máxima verosimilitud.
¿Modelos excluyentes o inclusivos?
La regresión logística, al clasificar los casos, adopta por defecto el procedimiento del punto de corte situado en 0,50. Si la probabilidad de participar estimada supera ese valor, entonces el caso es clasificado como “participante”. Pero esto es de algún modo arbitrario.
Supongamos que con ese valor de corte, el modelo es capaz de reconocer como participantes solamente al 60% de los hogares que lo son. Y a su vez, solamente se engaña clasificando un 2% de “falsos participantes” candidatos a grupo de comparación. Sería un modelo en exceso restrictivo, que incurre en muy poco error de inclusión y en demasiado error de exclusión.
Tendremos, pues, que regularlo. Si bajamos a 0,30, el modelo resultante clasifica correctamente a más del 80% de los participantes (redujo su error de exclusión) y en cambio “deja entrar” el triple de no participantes: alrededor de 6%. Es decir, aumenta su error de inclusión y se vuelve más admisivo, con lo que funciona mucho mejor a los efectos de nuestros requerimientos.
Restricciones
Deben tenerse en cuenta algunos preceptos para no “hacer trampas”.
Las variables sobre las que se esperan impactos del programa no deben formar parte del conjunto de variables independientes incluidas en el modelo (Caliendo y Copeinig, 2005). ¿Por qué? Pues porque si el programa tiene efectivamente impactos, el grupo de tratamiento y el de comparación no debiera esperarse que se asemejen en los valores de estas variables, sino que diverjan.
Por caso, si un programa de transferencias condicionadas incluye la obligación de escolarizar a los adolescentes, entonces esperaríamos que en los hogares beneficiarios la tasa de asistencia de los adolescentes fuera mayor que en el grupo de comparación. Si incluimos esta variable en el modelo estaríamos seleccionando hogares que tienden a ocultar el impacto del programa.
Otro tanto ocurriría con eventuales efectos no deseados. Cierta literatura señala que los PTC tienen impactos negativos sobre la tasa de actividad, especialmente en el caso de las mujeres. De manera que la tasa de actividad de los hogares (el porcentaje de miembros activos sobre el total de miembros, o mejor de miembros adultos) tampoco debiera emplearse como variable predictora. Porque contribuiría a seleccionar en el grupo de comparación hogares con similares tasas de actividad, con lo que podría disimular un eventual efecto reductor de la propensión a trabajar entre los beneficiarios, si es que realmente lo hubiera.
En otros términos, las variables independientes del modelo debieran ser “neutras” en cuanto a los efectos esperados del programa. En cambio, sí es posible y recomendable incluir variables relacionadas con los criterios de admisión, tales como la presencia de niños y adolescentes o la de trabajadores informales.
Y por cierto otras variables relacionadas con cierto “perfil” del hogar: el tamaño, la relación entre menores y total de miembros, el nivel educativo de los adultos.
¿Qué sucedería con los ingresos familiares? En principio, se diría que si ambas encuestas los han indagado de igual manera, podrían incluirse como predictores a condición de que, en el caso de los hogares realmente beneficiarios, pudieran restarse de los ingresos totales los que corresponden a la transferencia de la prestación del programa. Pero cabría una objeción: si existe el supuesto de que el ingreso de un PTC7 podría sustituir ingresos de otras proveniencias y alentar el retiro del mercado laboral de trabajadores con ingresos bajos, al restar los ingresos del PTC estaríamos subestimando los que realmente podría tener el hogar sin esa transferencia, con lo que sesgaríamos hacia abajo la selección del grupo de comparación.
Otra posible razón estriba en el carácter frecuentemente volátil de los ingresos monetarios de los hogares que suelen ser beneficiarios de programas sociales, como también de aquellos hogares que, sin serlo, se les asemejan. Estos hogares suelen tener miembros ocupados en puestos de trabajo del sector informal, frecuentemente inestables. Incluso la intensidad horaria de sus ocupaciones puede ser variable en lapsos relativamente cortos de tiempo. Por eso, parece más razonable nutrir el modelo con variables observables de carácter más estructural y permanente.
¿Cómo proceder?
El subconjunto de hogares que integran el error de inclusión –los “falsos participantes” – serán pues la cantera que permita conformar el grupo de comparación.
¿Cuál es el procedimiento a emplear para seleccionar el grupo definitivo? El procedimiento que sugiere la literatura (Rosenbaum y Rubin, 1985; Lazo y Philipp, 2003; Caliendo y Copeinig, 2005) es el del “vecino más próximo”. E indica que para cada caso integrante del grupo de tratamiento (excluidos previamente los atípicos a los que el modelo estadístico no pudo reconocer como tales y les otorgó baja propensión a participar) hemos de encontrar, dentro del subconjunto del “error de inclusión” o “falsos participantes” entre tres y cinco casos con una propensión a participar cercana.
Las distancias entre las propensiones (que se expresan siempre como probabilidades fijadas entre cero y uno) suelen medirse en términos cuadráticos. Es decir como diferencia elevada al cuadrado entre ambas probabilidades. Y será aceptable incluir en el grupo de comparación los tres o los cinco casos cuya distancia máxima con su correspondiente del grupo de tratamiento no supere 0,01 (Lazo y Philipp, 2003).
La idea es que por cada caso en el grupo beneficiario se cuente con tres o con cinco como controles. Dado que procuramos “aparear” beneficiarios con los más parecidos entre los no beneficiarios, es aceptable que un mismo caso del grupo de comparación pueda, simultáneamente, servir de equivalente para varios beneficiarios con los que guarde una diferencia reducida en la puntuación de la propensión a participar. Vale decir, no es necesario que el apareamiento sea uno a uno.
Las limitaciones
Por cierto que estas recomendaciones no siempre son fáciles de cumplimentar. La mayor de las dificultades es que el error de inclusión sea muy pequeño. Hay pocos hogares parecidos a los beneficiarios y que no lo sean. Esto ocurre especialmente cuando un programa muestra una cobertura muy extendida sobre la población meta.
Por ejemplo, no sería muy fácil encontrar hogares con menores a cargo de trabajadores informales y que no reciban la AUH. O también podría suceder que los que halláramos guardaran alguna diferencia esencial con los beneficiarios: por ejemplo podrían ser migrantes recientes cuyos hijos carecen de documento de identidad.
En parte, esto podría solucionarse mediante la admisión de unas diferencias más amplias al hacer el matching. O bien tornando mas lato el criterio del numero de “gemelos” en el grupo de comparación (Lazo y Philipp, 2003).
Puede ocurrir que algunos miembros del grupo de tratamiento directamente no encuentren gemelos en el grupo de comparación dentro del rango de puntuación aceptado en la diferencia de la propensión a participar. En este caso debieran ser excluidos (Caliendo y Copeinig, 2005). Y ello podría sesgar los resultados: supongamos por un momento que los impactos del programa fuesen menores –o mayores– en cierto tipo de hogares “atípicos”, que no obstante participar del mismo arrojen valores extremos (muy altos o muy bajos) en la puntuación de la propensión. Su exclusión conduciría a ocultar estos efectos diferenciales y con ello a sobrestimar o subestimar el impacto, según el caso.
Cómo calcular las diferencias
En el esquema clásico del diseño experimental, se supone que las diferencias debieran calcularse entre casos pareados.
Como habría en el grupo de comparación más de un caso gemelo por cada beneficiario (entre tres y cinco) los valores de estos casos en la/s variables/s testeadas debieran ser promediados y luego se calcularía, para cada una de estas variables, la diferencia entre el valor de cada caso integrante del grupo de tratamiento y el promedio de los valores de sus casos testigos o gemelos en el grupo de comparación.
Y luego, se promediarían las diferencias así obtenidas: ese promedio sería la diferencia entre el grupo de tratamiento y el grupo de comparación.
Este procedimiento no ofrecería dificultad si la variable o variables a testear (las de impacto del programa) fuesen variables cuantitativas: el número de controles realizados durante el embarazo o la cantidad de visitas al médico en el primer año de vida de un niño.
Pero más usualmente son categóricas. La asistencia o no a un establecimiento educativo o el hecho de estar o no estar inserto en el mercado de trabajo, por ejemplo.
Esto tendría una solución relativamente sencilla si estas variables se convierten en dummy con valor 1 para la respuesta afirmativa (asiste a la escuela, está inserto en la actividad económica, etc.) y valor 0 para la respuesta negativa (no asiste, no trabaja, etc.). Estos valores podrían promediarse para los casos gemelos del grupo de comparación, aunque esos promedios no serían ya cero y uno. Supongamos que un caso cualquiera del grupo de tratamiento tuviera tres equivalentes por puntuación próxima en el grupo de comparación. En el primero el jefe de hogar trabaja y recibe puntuación 1, mientras que en los tres hogares apareados hay dos que trabajan y uno que no: el promedio sería 0,666. Y la diferencia 0,333. La interpretación intuitiva de diferencias así obtenidas resultaría no obstante un tanto confusa y oscura.
Sin embargo, hay otra dificultad mayor cuando los elementos seleccionados no son individuos sino colectivos –como es el caso de los hogares– y cuando los presuntos impactos del programa son diversos y pueden manifestarse sobre distintos miembros de estos colectivos.
Al tratar de calcular las diferencias de hogar a hogar, en el caso de la asistencia escolar, que se calcula por edades diferentes (5 años, 6 a 12 años, 13 a 15 años, etc.), comprobaríamos que no todas las familias tienen niños situados en los mismos tramos de edad. Por ejemplo, en un hogar beneficiario puede haber un niño en edad de escolaridad primaria y un adolescente en edad de asistir al secundario. Pero en los hogares más próximos en la puntuación de la propensión a participar, no necesariamente habrá niños y adolescentes. Puede ser que haya unos u otros. Y la inexistencia de unos u otros hará imposible el cálculo de las diferencias en todos los tramos previstos.
Otro tanto sucedería con la inserción laboral de los varones adultos: podría no haberlos, por caso en los hogares monoparentales.
Si fuera necesario prever, al hacer el matching, formar subcategorías de hogares con conformaciones específicas antes de seleccionar los más próximos en las puntuaciones, la construcción del grupo de comparación se tornaría sumamente dificultosa. Y más probablemente imposible.
Una alternativa
Una alternativa por la que puede optarse para solucionar estos inconvenientes cuando los impactos del programa que deben verificarse son variados y afectan a diferentes miembros de los hogares involucrados, estriba en el cálculo global de las diferencias entre el grupo de tratamiento y el grupo de comparación y no caso a caso.
Si sencillamente se adopta como grupo de comparación el conjunto de los hogares que integran el error de inclusión y que cuentan con un hogar próximo en su “propensión a participar” entre los beneficiarios, desaparece la necesidad de correspondencia uno a uno entre niños de cada tramo de edad, por ejemplo. Simplemente hemos de computar, para cada grupo etario, la tasa global de asistencia de cada tramo de edad en un grupo y otro. Y las diferencias se computan de ese modo. Otro tanto se haría con las tasas de actividad o las de empleo masculinas, femeninas, etc.
Claro que, eliminado el matching caso a caso y simplemente ateniéndonos a un grupo de comparación conformado por el error de inclusión, surge naturalmente la necesidad de hacer algunos controles que nos permitan asumir el supuesto de la igualdad entre ambos grupos.
Los recaudos
Un primer recaudo consistirá en examinar el rango de las puntuaciones de “propensión a participar” tanto en los beneficiarios como en los que no lo son pero el modelo identificó como tales, así como sus dispersiones.
Si las puntuaciones mínimas y máximas fuesen muy diferentes, podrían eliminarse los casos extremos en ambos grupos con el propósito de atenuar estas diferencias. Inclusive, es posible emplear como grupos de impacto solo los subconjuntos de casos que guarden razonable proximidad. Esta posibilidad de usar solo los casos que se ubiquen en una zona de convergencia en cuanto a las puntuaciones, ha sido plenamente justificada por la literatura (Jalan y Ravallion, 1998).
Ello, no obstante, en el caso del grupo de tratamiento, reproduciría el riesgo de encubrir efectos diferenciales sobre casos extremos. Esto no ocurriría en el grupo de comparación, cuyos extremos podrían recortarse sin riesgo para asimilarlo al grupo de tratamiento.
Luego, se compararían las medias de las puntuaciones de uno y otro grupo con el test de t de Student para la diferencia de medias de muestras independientes: el propósito sería, en este caso, que pudiésemos conservar la hipótesis de nulidad que afirmaría que ambas muestras provienen de poblaciones con medias iguales.
Asimismo, los controles podrían replicarse para un conjunto de variables estructurales no vinculadas con los impactos esperados del programa. Por ejemplo, tamaño de los hogares, cantidad de menores, edades o niveles educativos de los jefes de hogar y o sus cónyuges, etc. Se esperarían que ambos grupos no difirieran de manera significativa en este tipo de características. Y ello también podría ser testeado con la prueba de t de Student para la diferencia de medias de muestras independientes (y su extensión al caso de las proporciones cuando se trata de variables categóricas). Nuevamente, el propósito de estos controles sería poder admitir la hipótesis de nulidad.
¿Doble ciego?
En un experimento –cualquiera que fuese– lo ideal es la aplicación del procedimiento denominado de “doble ciego”.
Esto es muy usual por ejemplo en los experimentos médicos. En un experimento de “doble ciego”, ni los individuos participantes que integran los grupos a comparar ni los investigadores que implementan el procedimiento saben quién pertenece al grupo de comparación (y recibe placebos) y quién al grupo experimental. Solamente después de haberse analizado todos los datos, y concluido el experimento, los investigadores conocen qué individuos pertenecen a cada grupo.
De esta forma se evita el riesgo de la introducción de sesgos en la evaluación de los resultados imputables a preconceptos por parte del que evalúa los mismos. Se busca con ello evitar que las expectativas del investigador influyan sobre el resultado observado.
Es preciso señalar que cuando empleamos el método de construcción estadística del grupo de comparación no es posible poner en práctica el experimento “doble ciego”, en tanto el propósito del modelo estadístico es reconocer a los verdaderos participantes: esa es la variable dependiente que se procura predecir.
Y esperamos que el modelo atribuya equivocadamente esa condición a no participantes que se les parezcan lo suficiente, asignándoles una “propensión a participar” próxima a la de los miembros del grupo de tratamiento.
Estas posiciones no se pueden invertir. Si ignoráramos cual es cual, podríamos construir un modelo que fuera capaz de reconocer a no participantes. Por ejemplo, sujetos en su mayoría sistemáticamente más ricos que los participantes. Y luego les apareara a algunos de estos últimos, atípicos, que se les asemejaran. Esta inversión, obviamente, sesgaría totalmente los resultados.
3. Un ejemplo de aplicación
A continuación se exponen resultados de la aplicación del procedimiento que hemos estado considerando para la selección del grupo de comparación en la evaluación de un programa de transferencias de ingresos condicionadas (PTC) que, en el marco de esta exposición, denominaremos Plan Solidario.
Los cuadros que se muestran –las salidas resultantes de la aplicación del modelo– son los resultantes de una de las pruebas previas. En la evaluación final se empleó un modelo muy semejante pero no igual.
El Plan Solidario consiste en un programa de transferencias de ingresos condicionadas (PTC) a hogares de bajos ingresos. Conlleva por lo tanto contraprestaciones –mejor, “corresponsabilidades”(Mazzola, 2012) – por parte de los hogares beneficiarios que incluyan niños y adolescentes: de asistencia a un establecimiento educativo en las edades obligatorias y de cumplimiento del plan de vacunación vigente en el caso de los niños.
Puesto que los ingresos de los hogares no son comprobables cuando sus miembros (o al menos algunos de ellos) no son trabajadores asalariados registrados en la seguridad social –y esta es la situación más frecuente entre los hogares de bajos ingresos– se aplica un proxy means test para la admisión de los hogares postulantes al programa que, en caso de dudas se complementa con procedimientos de análisis cualitativo mediante visitas y entrevistas.
Una vez admitidos al programa los hogares reciben una prestación monetaria que depende de su composición y tamaño. Pasado cierto tiempo desde la iniciación de las acciones del Plan Solidario se trata de evaluar sus eventuales impactos. Seguramente los gestores de la política se preguntarán si ella ha arrojado los resultados esperados: los hogares mejoraron su nivel de vida, los niños y adolescentes asisten más a la escuela, se hacen más controles médicos preventivos y se vacunan más, etc.
Asimismo –y puesto que los PTC son frecuente objeto de críticas– también habrá de verse si la recepción de un ingreso complementario no ha desalentado las búsquedas laborales e incentivado a los miembros de los hogares a trabajar menos, lo que sería un efecto no deseado de la política. Para todo ello, es preciso contar con un grupo de comparación compuesto por hogares de características estructurales semejantes a las de los que reciben el programa (“elegibles”, digamos), pero que no hayan sido beneficiarios del mismo.
Las similitudes, sin embargo, no deben fincar en aspectos sobre los que se espera que el programa tenga efectos. No tendremos que seleccionar hogares donde los niños asistan en la misma proporción a la escuela, por caso, puesto que esperamos que el programa establezca una diferencia en este punto. Si así lo hiciésemos estaríamos “forzando” a los hogares del grupo de comparación a tener tasas de asistencia escolar similares a las del grupo de tratamiento y eso tendería a encubrir el impacto del programa, jugándonos en contra. Tampoco los ingresos serán una variable de selección, porque justamente la política que estamos evaluando consiste en proporcionar ingresos adicionales.
Aunque en este caso se podría emplear el ingreso descontando la prestación del programa, tampoco resulta del todo aconsejable. Pues en los sectores más vulnerables los ingresos suelen ser variables y poco estables, porque también las ocupaciones lo son.
Es mejor, pues, apelar –más que a los ingresos presentes– a la capacidad potencial de obtenerlos. Así como las necesidades de los hogares para la subsistencia. Así, los niveles educativos de los adultos, el tamaño y conformación de los hogares, la disponibilidad de fuerza de trabajo y el tipo de inserción laboral de los miembros en edad de trabajar, sí que pueden ser variables de selección. En este último caso, porque permitiría discriminar “negativamente” a los hogares con miembros insertos en forma estable en el mercado de trabajo formal, que en rigor resultan menos “elegibles” y por lo tanto no abundan entre los beneficiarios.
En el ejemplo que aquí se presenta, las variables seleccionadas como independientes fueron:
- Tenencia precaria de la vivienda (Tempre)8
- Cantidad de menoresde18 años en el hogar (Men18_1)
- Jefe del hogar con baja educación (jebajed_1)9: variable dummy
- Jefe de hogar trabajador protegido (jeprot_1)10: variable dummy
- Tasa de dependencia económica del hogar (tasdep)11
- Tasa de cobertura de salud del hogar (tasalud)12
- Total de miembros del hogar (pobtot)
- Hacinamiento en la vivienda (hacinam)13: variable dummy
A continuación la tabla de clasificación resultante:
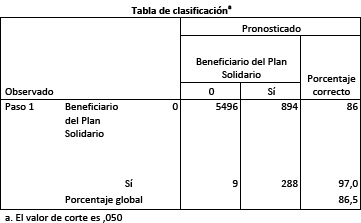
Como puede apreciarse, el modelo reconoce adecuadamente al 97% de los hogares realmente beneficiarios. Tiene un error de tipo I o de exclusión muy bajo (apenas 9 de los 297 hogares beneficiarios presentes en la muestra fueron erróneamente clasificados como no beneficiarios). Pero en cambio, el error de admisión es afortunadamente mayor: puesto que 86% de los hogares no participantes son correctamente clasificados, hay 14% (894 hogares) que son “confundidos” con los participantes; candidatos a integrar el grupo de comparación.
El ajuste del modelo se revela, pues, altamente satisfactorio. Veamos ahora la significación de cada una de las variables predictoras:
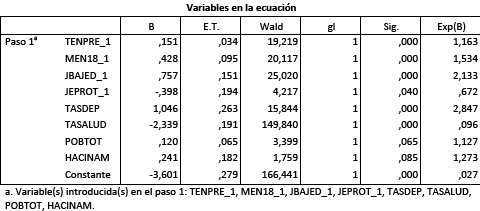
Todas ellas se muestran significativas a través del estadístico de Wald: prueba de significación cuya hipótesis nula es que los coeficientes B de la regresión logística son iguales a cero (Hosmer y Lemeshow, 2000). En todos los casos es posible rechazar esta hipótesis nula con una probabilidad de error siempre menor a 10% (8,5% en el caso del hacinamiento).
Los coeficientes B tienen, asimismo, los signos teóricamente esperados: por caso, la tenencia precaria de la vivienda, la cantidad de menores presentes en el hogar, el tamaño del hogar o la presencia de un jefe con baja educación aumentan la probabilidad de participar del programa. En tanto que la presencia de trabajadores protegidos o de personas con cobertura de salud la disminuyen.
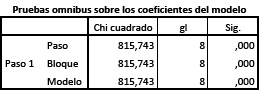
En la siguiente tabla (prueba ómnibus sobre los coeficientes del modelo) se muestra una prueba Chi Cuadrado que evalúa la hipótesis nula de que los coeficientes B de todas las variables introducidas, a excepción de la constante, son cero. Este estadístico está obtenido por diferencia entre los valores del – 2LL antes y luego de la introducción de las variables independientes. La significación de Chi cuadrado (menor a 0,001) nos permite rechazar tal hipótesis nula sin vacilación alguna.
Las R cuadrado de Cox y Snell y Nagelkerke son interpretables como proporción de varianza explicada. Los valores obtenidos no fueron altos, como lo muestran las salidas. Nuevamente, la razón es que se espera que en este empleo del modelo logístico haya un error clasificatorio, que nos permita obtener “no participantes” parecidos a los “participantes”. Así las variables independientes estarán lejos de agotar las fuentes de variación de la variable dependiente (“participación/no participación”).


Finalmente, se testea también la significatividad global del modelo con la prueba de Hosmer y Lemeshow. Se trata de una prueba de significación estadística cuya hipótesis de nulidad supone que los estados observados no difieren de las predicciones. Esta hipótesis de nulidad, en este caso pudo ser rechazada con una probabilidad de error de tipo I (rechazar una hipótesis nula verdadera) muy baja: 2%. Cuando, prima facie, se trataría de un indicador desfavorable para evaluar un modelo: se diría que entonces clasifica mal, incurre en errores clasificatorios. Pero en este uso del modelo, dichos errores son –ya se lo ha dicho– deseables. Esperamos que el modelo “se confunda” y tome a algunos “no beneficiarios” por “beneficiarios”, estimándoles una “probabilidad de participar” (propensity score) cercana a los primeros. De no haber este error de admisión, no tendríamos grupo de comparación. Es decir, en este caso se trata de un error deseable. En cambio, hemos de esperar que los verdaderos beneficiarios sean reconocidos con poco error de exclusión: así sucede, felizmente, con el 97% de ellos.
Conclusiones
La evaluación del impacto de las políticas responde a la necesidad de comprobar si los objetivos previstos en las mismas se cumplen. Este breve artículo abordó el uso de la regresión logística binaria para solucionar algunas dificultades propias de la evaluación de políticas y programas sociales, ante la imposibilidad de emplear diseños experimentales puros y sin contar con línea de base.
Sin ignorar los reparos y recaudos que deben tenerse en cuenta en el empleo de grupos de comparación construidos mediante métodos estadísticos, este procedimiento se revela como una solución subóptima y un fértil recurso en la evaluación de impacto de las políticas públicas.
No obstante, y teniendo en cuenta la creciente necesidad de dar cuenta del resultado de las acciones del Estado que demandan recursos provenientes del conjunto de los contribuyentes, se remarca la importancia de que la planificación de las políticas prevea instancias de evaluación futura y contemple mediciones de línea de base que incluyan, siempre que sea posible, población no inserta en el programa a evaluar o cuyo ingreso al mismo se vea diferido. Ello, con el objetivo de poder emplear el procedimiento de la “diferencia de diferencias” sin el requisito de asumir el exigente supuesto de la equivalencia inicial en ausencia de la medición previa al inicio de las acciones del programa que, como hemos visto, exige la medición ex post.
Pero toda vez que ello no siempre es posible, se espera que el presente artículo sea una contribución a la tarea de quienes deben asumir la tarea de evaluar las políticas públicas.
Notas
Austin, P. (2011). “An Introduction to Propensity Score Methods for Reducing the Effects of Confounding in Observational Studies”. Multivariate Behavioral Research, 46:3, 399-424, DOI: 10.1080/00273171.2011.568786.
Baker, J. (2000). Evaluación de impacto de los proyectos de desarrollo en la pobreza. Manual para profesionales. Washington D. C.: Banco Mundial.
Caliendo, M. y Copeinig, S. (2005). Some Practical Guidance for the Implementation of Propensity Score Matching. Forschungsinstitut zur Zukunft der Arbeit Institute for the Study of Labor. Discussion Paper No. 1588. Bonn, Germany.
Hair, J., Anderson, R., Tatham, R y Black, W. (1999). Análisis Multivariante. Madrid: Prentice Hall.
Heinrich, C., Maffioli, A. y Vázquez, G. (2010). A Primer for Applying Propensity-Score Matching Impact-Evaluation Guidelines. Technical Notes. Inter-American Development Bank.
Hosmer, D. W. y Lemeshow, S. (2000). Applied Logistic Regression. New York: John Wiley & Sons, INC.
Jalan, J. y Ravallion, M (1998). “Income Gains from Workfare: Estimates for Argentina’s TRABAJAR Program Using Matching Methods.” Washington, D.C.Development Research Group, Banco Mundial.
Lazo, T. y Philipp, E. (2003). “Uso de la regresión logística para la construcción de un grupo de control” en Lago Martínez, S., Gómez Rojas, G. Y Mauro,M. (coordinadoras): En torno de las metodologías: abordajes cualitativos y cuantitativos. Buenos Aires: Editorial Proa XXI.
Mazzola, R. (2012). Nuevo Paradigma. La Asignación Universal por Hijo en la Argentina. Buenos Aires: CEDEP (Centro de Estudios y Desarrollo de Políticas)/Prometeo.
Rosenbaum, P. y Rubin, D. (1985). “The central role of propensity score in observational studies for causal effects”. Biométrica Nº 70. Great Britain.
RAESTA 3 - Año 3 (2016)
Presentación
Artículos
Desempeño de las PyME industriales argentinas, 2005-2011: Medición de eficiencia en la producción a través de un enfoque no-paramétrico. +Laura MastroscelloAnálisis multivariado aplicado a la generación de escenarios complejos en torno a concepciones de sexualidad y género en alumnos de escuelas medias. +Sebastián Ezequiel SustasLucas KlobovsLiliana Pascual“El análisis de redes sociales como herramienta para focalizar la intervención en entornos rurales a través de políticas públicas. +Nicolás Vladimir Chuchco / Cintia Noelia Díaz / María Leonor Pérez BrunoNicolás Sacco
RAESTA 2 - Año 2 (2015)
Editorial
Artículos
Bruno De SantisConstrucción de un índice del nivel socioeconómico del hogar urbano en la República Argentina mediante el análisis de correspondencia múltiple y escalamiento óptimo. +María Fernanda Artola / Iván Redini BlumenthalOrientaciones de futuro laboral y educativo de estudiantes secundarios. Análisis multivariado en un diseño muestral complejo. +Rosario AustralMarcelo Bergman / Diego Masello / Christian Arias / Guadalupe Peralta AgüeroUn ejemplo de diseño cuasi experimental: uso de la regresión logística binaria en la construcción de un grupo de comparación para la evaluación de impacto de un programa social. +Horacio ChitarroniMetodología estadística para la estimación de las superficies sembradas con cultivos extensivos - método de segmentos aleatorios. +Norberto V. Rodríguez / Julieta Mirensky
RAESTA 1 - Año 1 (2014)
Editorial
Artículos
La pérdida de valor de las credenciales educativas en el mercado de trabajo Argentino 1995-2001. Una respuesta desde los métodos estadísticos. +Florencia SourrouilleLos docentes en la Encuesta Permanente de Hogares. Notas metodológicas para su identificación y estudio. +Leandro BottinelliEspecificación del modelo, datos faltantes y casos atípicos: la “trastienda” de una investigación basada en el análisis de la varianza. +Luisa IñigoAna María Capuano