La pérdida de valor de las credenciales educativas en el mercado de trabajo Argentino 1995-2001. Una respuesta desde los métodos estadísticos.
En este trabajo se sostiene que durante la segunda mitad de la década de 1990 se desarrolló un proceso de pérdida de valor de las credenciales educativas de los trabajadores con nivel de estudios secundario completo o mayor. Como a su vez en el período se incrementó la desigualdad salarial se sostiene que lo que se observa es un fenómeno de dos aristas: de devaluación educativa y segmentación del mercado de trabajo. Para realizar estas afirmaciones se utilizan regresiones lineales múltiples para el cálculo de premios salariales. Dado que la fuente utilizada es una muestra y el universo es pequeño se utilizan pooles de datos para ampliar la cantidad de muestra disponible y mejorar las estimaciones. Se desarrolla una metodología cuyo objetivo es poder decidir desde el punto de vista estadístico si los pooles de datos pueden ser utilizados o no en cada problema de trabajo y como trabajar con ellos, y así poder utilizar los recursos disponibles bajo el control de métodos estadísticos.
Los docentes en la Encuesta Permanente de Hogares. Notas metodológicas para su identificación y estudio.
El estudio de los docentes como colectivo laboral en Argentina puede ser realizado con precisión a partir de los Censos Nacionales de Docentes. Estas fuentes de información son específicas del sector educativo y, por lo tanto, las más idóneas para la caracterización detallada de los cargos, horas, funciones, trayectorias y formación de los docentes. Sin embargo, sus principales limitaciones son la periodicidad decenal y las dificultades para comparar a los docentes con otros grupos laborales. La Encuesta Permanente de Hogares, fuente diseñada para caracterizar y monitorear la inserción laboral de la población, permite suplir las limitaciones mencionadas en el estudio de los ocupados en las actividades de enseñanza. Sin embargo, tiene ciertas características y limitaciones que resultan importantes tener en cuenta al utilizarla para estudiar el colectivo docente. Este artículo analiza la fuente en cuanto sus potencialidades para el estudio de este grupo laboral. Concluye que es consistente para el estudio de la evolución del empleo docente.
Especificación del modelo, datos faltantes y casos atípicos: la “trastienda” de una investigación basada en el análisis de la varianza.
El artículo está centrado en la discusión de aspectos metodológicos de la investigación de tesis de la autora. En el campo de los estudios sobre la distribución personal del ingreso y los mercados de trabajo resulta habitual el análisis de la regresión del ingreso personal contra diversos atributos de los perceptores y sus ocupaciones. Este análisis tiene por requisito la resolución de cuestiones referidas a: la definición del modelo en que estará basado, el tratamiento que se dará a los casos sin información y los procedimientos mediante los que se evaluará y, eventualmente, corregirá la influencia de los casos extremos sobre los parámetros estimados. El artículo refiere qué decisiones fueron tomadas en la investigación a este respecto, fundamentando las razones y describiendo su impacto sobre los resultados obtenidos.
¿Qué son los Indicadores? Perspectivas y usos diferentes.
El presente artículo tiene como objetivo presentar las diferentes perspectivas y usos de los indicadores, por un lado, desde las ciencias sociales y por otro desde lo que se denominó “Movimiento de Indicadores Sociales”. En términos generales, el uso de los indicadores ha sido utilizado desde el enfoque de las ciencias sociales para medir empíricamente conceptos teóricos que permitan el abordaje empírico a los fenómenos sociales. Sin embargo, los indicadores son también utilizados desde una perspectiva más pragmática, principalmente por los organismos de estadística y organismos internacionales. A través del artículo se presentan los diferentes recorridos realizados por las perspectivas mencionadas. En la primera parte se describe la medición empírica de conceptos a través de indicadores en los principales referentes de las ciencias sociales. En la segunda parte se describe el contexto de surgimiento y el desarrollo de lo que se denominó “Movimiento de Indicadores Sociales” como otra forma de aproximación al estudio de la realidad social a través de indicadores. En la tercera se problematiza las diferencias de ambas perspectivas en cuanto a los objetivos y el método que utilizan y se presenta como conclusión la importancia de vincular ambas perspectivas.
Aportes al estudio de la opinión pública en las elecciones presidenciales 2007 en Argentina.
El presente trabajo intenta explorar la creciente importancia que los estudios de opinión pública han comenzado a tener durante las últimas décadas. En este sentido, se busca brindar un aporte a la investigación dentro de una actividad que siempre ha estado más bien alejada del ámbito académico, en especial en los estudios relacionados con los procesos electorales. Asimismo, el trabajo intenta develar la notable injerencia que los medios de comunicación tienen en los procesos electorales de los últimos años, demostrándose que se trata de una tendencia que va tomando cada vez más impulso. Finalmente, se analizaran cuestiones que resultan un aporte para diagnosticar los cambios en las percepciones de la ciudadanía durante la etapa previa y posterior a una elección.
Construcción de un índice del nivel socioeconómico del hogar urbano en la República Argentina mediante el análisis de correspondencia múltiple y escalamiento óptimo.
El trabajo presenta la construcción de un índice que tiene como finalidad asignar a cada hogar urbano de la República Argentina un nivel socioeconómico. Se piensa al índice como una variable latente (no observable) y se aplica el análisis de correspondencia múltiple, método exploratorio de estadística multivariada, para obtener los ponderadores (pesos) de las modalidades de las doce variables seleccionadas.
El índice se compone de variables relativas a las características de la vivienda, la condición laboral y educativa del jefe de hogar y del cónyuge. La metodología se aplica a la Encuesta Nacional de Gasto de los Hogares 2012/2013 (Instituto Nacional de Estadísticas y Censos). Una vez estimados los puntajes de la variable latente para los hogares urbanos, se establecen los quintiles socioeconómicos y se asigna a cada hogar un quintil. Finalmente, se analizan las características de cada uno de los quintiles obtenidos y se indican las fortalezas y limitaciones de la metodología.
Orientaciones de futuro laboral y educativo de estudiantes secundarios. Análisis multivariado en un diseño muestral complejo.
En este artículo se analizan las orientaciones de futuro laboral y educativo de los estudiantes que a fines de 2008 cursaban el último año de estudio en las escuelas estatales de la Ciudad Autónoma de Buenos Aires. En primer lugar, se describen las orientaciones de futuro hallándose una prevalencia de proyectos educativo-laborales entre los estudiantes y una anticipación de obstáculos que resulta más pronunciada en el plano laboral que en el educativo. Luego, mediante un análisis de regresión logística multivariada, se compara la influencia relativa de distintos atributos sociales, escolares, biográficos y de la oferta educativa sobre los objetivos de tipo profesional. Entre los principales resultados se halla que las diferencias de género muestran contundencia en la priorización de un objetivo profesional. La modalidad del plan de estudios también emerge como un aspecto clave en los horizontes de futuro, observándose un hiato entre la formación bachiller-comercial y la técnica, donde prevalecen expectativas de inserción laboral directa luego del egreso. Otro hallazgo es que en el plano educativo los horizontes de profesionalización adquieren una difusión más amplia e independiente del origen social educacional, como reflejo de un contexto donde están dadas ciertas condiciones para el acceso masivo a la educación superior. Por otra parte, en el trabajo se enfatiza la importancia de considerar la complejidad del diseño muestral en la instancia de análisis de los datos. Para ello se comparan los resultados obtenidos con estimadores que consideran la complejidad de diseño muestral con otros “naive”, reflexionando acerca de las implicancias epistemológicas que esto conlleva en la puesta a prueba de hipótesis en el análisis bivariado y multivariado.
“Condiciones de socialización, entorno y trayectoria asociados a la reincidencia en el delito”.
En la actualidad el delito y la punición son analizados desde diferentes enfoques, ya que además de estar en crisis son temas a los cuales se les busca encontrar respuestas y soluciones. Es sabido entre los expertos que estudian estos tópicos que dentro de las cárceles la población es mayoritariamente joven, con bajos niveles de educación y provenientes de clases socioeconómicas medias/bajas y bajas, caracterizadas, entre otras cosas, por los bajos niveles de ingreso.
Teniendo en cuenta estas características podría pensarse que la vinculación explicativa de una conducta delictiva está dada por la asociación entre la condición de pobreza de un hogar y/o de sus integrantes y las probabilidades de comisión de delitos y la reincidencia en los mismos. Sin embargo, en este documento proponemos la existencia de una relación mucho más compleja. Por lo tanto, cabe preguntarse en relación al delito y a la reincidencia en el mismo, ¿qué tan asociados están esos factores a quienes incurren nuevamente en una conducta delictiva y al nivel de violencia al momento de perpetrar un delito?, finalmente, ¿qué factores son estos?
Para responder a estas preguntas se realizó un modelo de análisis multivariado basado en una regresión logística, en el cual se incorporaron variables relacionadas con los entornos o contextos de socialización temprana de los sujetos así como la trayectoria en instituciones como los institutos de menores. Los datos utilizados pertenecen a la Encuesta a Población en Reclusión de 2013, en la cual para Argentina se aplicaron más de mil encuestas personales a presos condenados por la justicia federal y ordinaria de la Capital así como por la justicia de la Provincia de Buenos Aires. Cabe destacar, además, que este fue un estudio que abarcó un conjunto de otros cinco países de la región: Brasil, Chile, El Salvador, México y Perú.
Un ejemplo de diseño cuasi experimental: uso de la regresión logística binaria en la construcción de un grupo de comparación para la evaluación de impacto de un programa social.
Este artículo trata acerca del empleo de la regresión logística binaria para la construcción de un grupo de comparación útil para la evaluación de impacto de un programa social. Se basa en una experiencia de aplicación real de tal procedimiento.
En la primera parte se aborda brevemente la problemática que plantea la implementación de diseños puramente experimentales en el caso de la evaluación de políticas públicas de contenido social y la alternativa de emplear modelos cuasi experimentales con un grupo de comparación construido estadísticamente. También se ponen en consideración algunas cuestiones inherentes a los diseños con doble medición, al tiempo que se abordan las dificultades que plantea la frecuente ausencia de una línea de base en el caso de los programas sociales. Asimismo, se explicitan los requisitos que debieran cumplimentar los grupos de comparación construidos mediante modelación estadística.
La segunda parte se refiere a las características del procedimiento estadístico empleado (la regresión logística binaria) y su utilidad específica para la obtención de grupos de comparación, con las limitaciones e inconvenientes que plantea, las alternativas posibles para sortearlos y los recaudos a adoptar. Finalmente, en la última parte se exponen los resultados provenientes del ejemplo de aplicación de este procedimiento conjuntamente con la interpretación de los mismos.
METODOLOGIA ESTADISTICA PARA LA ESTIMACION DE LAS SUPERFICIES SEMBRADAS CON CULTIVOS EXTENSIVOS - METODO DE SEGMENTOS ALEATORIOS.
El conocimiento de la superficie sembrada con cultivos extensivos es de relevancia estratégica para el país y necesita ser estimada en forma objetiva dos veces al año para las principales Provincias Argentinas. El método aquí propuesto es el de observar –con el significado literal de la palabra- una muestra de segmentos que se definen, como relativamente pequeñas áreas que toman la forma de polígonos rectangulares, sin consultar a los dueños de las tierras, a los productores ni a ninguna persona relacionada con las explotaciones que contiene el segmento.
La selección original es de puntos aleatorios dentro de estratos de uso homogéneo del suelo, que luego se los transforma en segmentos. Es obvio que gran parte de los puntos caerán en lugares que no se pueden acceder con un vehículo y para poder llevar a cabo la observación es necesario trasladar el punto hasta el camino más próximo y allí conformar el segmento. Desde el punto de vista de la teoría del muestreo se reconoce que el procedimiento de trasladar origina un sesgo el cual es un error no debido al muestreo.
La contrapartida es que el método tiene importantes ganancias, entre ellas: a) muy alta confiabilidad de los datos por provenir de observaciones “in situ” hechas por expertos, b) no hay error en la medida de las superficies por utilizar tecnología satelital, c) una vez definido el segmento el Sistema de Posicionamiento Global (GPS) permite controlar el operativo y anula el error de ubicación de los segmentos en futuros operativos, d) las muestras son altamente comparables en el tiempo, e) los resultados se obtienen en breve tiempo, en general no más de tres meses, f) reducción notable del presupuesto al no existir revisitas.
El método incorpora nuevas tecnologías, entre ellas: imágenes satelitales, Sistemas de Información Geográfica (GIS), el GPS, el uso del Índice de Vegetación de Diferencia Normalizada (NDVI), programas de procesamiento de la información y protocolos estrictos de procedimientos.
Desempeño de las PyME industriales argentinas, 2005-2011: Medición de eficiencia en la producción a través de un enfoque no-paramétrico.
Este trabajo mide la eficiencia en la producción de las PyME industriales argentinas a partir de la productividad total de los factores, para el período 2005-2011, utilizando datos a nivel empresa, y aplicando el enfoque Análisis Envolvente de Datos (DEA por sus siglas en inglés) basado en el trabajo de Farrell (1957) y las extensiones introducidas por Charnes et al (1978) y Banker et al (1984). Se busca generar un aporte desde el punto de vista metodológico, como antecedente en lo referido a cómo puede medirse la eficiencia de las PyME industriales argentinas en base a información estadística disponible, y explorar cuáles son los factores determinantes de la misma, ya que hasta el momento hay un vacío de información en este sentido. A partir de esto, se explora la asociación de este nivel de eficiencia con factores exógenos a las empresas o internos a las mismas como potenciales determinantes del mismo. Se encuentra que las PyME localizadas en las regiones del país de mayor desarrollo relativo y concentración de la actividad económica tienen un nivel de eficiencia en promedio mayor al resto. Mientras que, sorprendentemente, no hay evidencia suficiente para suponer que el sector de actividad de pertenencia está relacionado con el nivel de eficiencia en la producción. Por otro lado, contrariamente a lo esperado, las empresas más grandes, que exportan, y que solicitan y obtienen créditos bancarios, registran en promedio menores niveles de eficiencia que el resto, aunque esto podría explicarse por el hecho de que estas firmas están más capitalizadas, lo que, al incrementar su dotación del factor de producción capital, impacta negativamente en su eficiencia técnica de producción.
Análisis multivariado aplicado a la generación de escenarios complejos en torno a concepciones de sexualidad y género en alumnos de escuelas medias.
En el presente artículo se exponen aspectos analíticos y metodológicos de la aplicación de diversas técnicas de análisis de datos multivariados empleadas en una investigación sobre salud sexual y reproductiva y educación sexual. Se propone la categoría de escenarios complejos como construcción analítica que permite poner en vinculación concepciones, creencias y actitudes sobre sexualidad, diversidad sexual, género y aborto en base a un relevamiento por encuestas estructuradas en mujeres y varones adolescentes escolarizados en el nivel medio de Argentina realizado durante el segundo semestre del 2012. Dicho relevamiento tuvo como propósito principal indagar y explorar las formas en que determinadas concepciones sobre la sexualidad y el género de los alumnos se vinculan con modelos de educación sexual, las temáticas priorizadas en dichos abordajes, las formas en que se establecen los vínculos con docentes y adultos, los vínculos afectivos intrageneracionales, y las instancias de subjetivación juvenil. Se aplicaron una serie de técnicas estadísticas multivariadas: análisis de componentes principales, análisis de cluster por el método de K-medias y, fundamentalmente, el análisis de correspondencias múltiples para la generación de los escenarios complejos.
Las elecciones a Presidente de Argentina en 2011 y 2015.
La elección a Presidente en Argentina de 2011 tuvo como ganadora a la candidata por el Frente para la Victoria Cristina Kirchner con una amplia diferencia respecto al segundo. El triunfo de la candidata tiene diferentes explicaciones causales desde el punto de vista de las motivaciones del voto por parte del electorado. A través de la presente investigación se intenta identificar las variables condicionantes y jerarquizarlas. Las características socio demográficas del ciudadano no tienen la influencia de otros momentos. En cambio, variables relacionadas con la gestión, el posicionamiento de los candidatos y el vínculo entre Néstor Kirchner y su esposa adquieren mayor protagonismo como condicionantes del voto.
El triunfo de Mauricio Macri en la elección presidencial de 2015 también tiene sus explicaciones causales. Sin entrar en la profundidad de la elección de 2011, se encontraron aspectos ideológicos y vinculados al consumo como elementos motivadores del voto.
Las estadísticas educativas y los desafíos futuros: un sistema de información por alumno.
Este trabajo analiza tanto los antecedentes como las características actuales del sistema de información estadística del sistema educativo argentino. Se plantea también el camino futuro de este sistema, teniendo en cuenta los cambios tecnológicos que tuvieron lugar en nuestro país en los últimos años.
Actualmente, el sistema nacional de información educativa está basado, principalmente, en el Relevamiento Anual, operativo censal que recoge con un corte anual la información consolidada a nivel nacional sobre las principales variables del sistema educativo, exceptuando las universidades. Este sistema garantiza una información homogénea y comparable para todo el ámbito nacional.En la actualidad el sistema de información educativa enfrenta nuevos desafíos producto de un sistema educativo complejo y en constante transformación. Además, el Relevamiento Anual presenta varias limitaciones y solo permite analizar en forma parcial los nudos críticos del sistema educativo. Para paliar estas limitaciones, durante los años 2013 y 2015, se desarrolló un Sistema Integral de Información Digital Educativa —SInIDE—, basado en información nominal de los alumnos. Este nuevo sistema articula y compatibiliza los requerimientos de información de las distintas instancias de gestión en los niveles nacional y jurisdiccional y permite que las instituciones educativas desarrollen a través de este sistema sus propios procesos administrativos y pedagógicos. Su potencialidad radica en la posibilidad de acelerar todos los procesos y de recoger datos adicionales para diagnosticar el funcionamiento del sistema educativo y las trayectorias educativas de los alumnos, tanto a nivel de los establecimientos como a nivel provincial o nacional. Además, permite la construcción de nuevos indicadores para evaluar la situación del sistema educativo en todo el país, fortaleciendo las políticas que se llevan a cabo en el marco de la Ley de Educación Nacional.
El análisis de redes sociales como herramienta para focalizar la intervención en entornos rurales a través de políticas públicas.
Este trabajo muestra los resultados mediante la aplicación de un instrumento de recolección de datos reticulares para un estudio de línea de base y evaluación de políticas públicas en entornos rurales, a fin de describir, medir y comparar las formas de las asociaciones entre los agentes involucrados de dos cooperativas.
Los objetivos de la ponencia radican en describir y caracterizar las redes de asociaciones de pequeños productores rurales en un contexto social delimitado, y evaluar la viabilidad de complementar los análisis estadísticos cuantitativos tradicionales con la metodología del análisis de redes sociocéntricas, para focalizar las formas de intervención y detectar asociaciones latentes y potenciales.
Los resultados obtenidos al aplicar este instrumento en dos agrupaciones de pequeños productores rurales del Noroeste argentino, beneficiarios de un programa social en el año 2014, muestran dos grafos multiplexados diferenciados. Mientras que en la primera red la forma de las asociaciones para movilizar recursos estratégicos se encuentra restringida por la autoridad de los referentes de la organización, en la segunda se observa una distribución más equitativa y menos autoritaria de los vínculos, así como una intermediación menos centralizada.
Se concluye que esta metodología ha sido adecuada para describir las fuerza, dirección y circulación de las relaciones entre los nodos de las agrupaciones relevadas, así como la existencia de asociaciones potenciales que no sean efectivizado. De esta forma la toma de decisiones se ve beneficiada al disponer de información específica, que permite detectar la necesidad de fortalecer vínculos, así como la posibilidad de identificar nodos y subgrupos que centralizan la intermediación y los recursos o que pueden desarrollar una mejor circulación de los mismos a causa de sus posiciones estratégicas en las redes.
Las clases sociales según los censos de población de 1991 y 2001.
El artículo presenta una metodología para la reconstrucción de las series del Nomenclador de Condición Socio-Ocupacional y el esquema de clases de Torrado a lo largo del período 1980-2001, durante el cual los cambios en los sistemas clasificatorios de las variables involucradas en su construcción presentaron importantes cambios. Se utilizaron los datos secundarios del estudio “Estructura Social Argentina” del Consejo Federal de Inversiones para el censo de 1980 y los datos publicados por el Instituto Nacional de Estadística y Censos de los censos de población de 1991 y 2001, para el Total del País.
La investigación aborda tanto las cuestiones metodológicas enfrentadas a la realidad de la oferta estadística en Argentina así como también aspectos teóricos sobre la temática de la estructura social. Se realiza un detallado análisis de las fuentes existentes que permiten la construcción de series lo más homogéneas posibles en términos metodológicos con el objetivo de que muestren los cambios de la estructura social entre fines de los cuarenta y la actualidad. Se analizan también los resultados alcanzados. En lo que hace a este aspecto, sin embargo, la profundidad de la indagación es menor.
El aporte permite continuar y armonizar, con las dificultades y advertencias metodológicas que implica, los trabajos de Germani (1955) y Torrado (1992) y el análisis de la estructura social Argentina según datos secundarios cuantitativos.
Palabras clave: Condición Socio-Ocupacional; clases sociales; censos de población; estructura social argentina; mercado de trabajo; ocupación; empleo.
RAESTA 1 - año 1 (2014)
Artículos
Especificación del modelo, datos faltantes y casos atípicos: la “trastienda” de una investigación basada en el análisis de la varianza
Luisa Iñigo1

1. Introducción
El propósito del presente artículo es comentar algunas decisiones metodológicas y técnicas tomadas durante el proceso de investigación de la Tesis de Maestría “Escolaridad y diferenciación de la fuerza de trabajo en el Gran Buenos Aires, 1985-20052”.
El análisis de la correlación entre el salario (o, más en general, el ingreso personal) y diversas características de los perceptores y sus trabajos, a partir de datos de la EPH, es relativamente frecuente en el campo de las ciencias sociales argentinas en los estudios referidos a la distribución personal del ingreso o a las características de los mercados de fuerza de trabajo. Para hacer dicho análisis, es necesario comenzar por tomar una serie de decisiones que van desde las más obvias, como la especificación del modelo, hasta otras más discretas, como el tratamiento que se dará a los casos con información faltante o a los casos atípicos.
Sobre este último tipo de decisiones, sólo ocasionalmente se encuentran referencias explícitas en los informes de investigación que llegan al público. En cuanto a la especificación general del modelo que representará la variabilidad salarial, normalmente la selección de variables regresoras es fundamentada a partir de un desarrollo conceptual y el foco específico de atención de cada investigación. Sin embargo, el proceso que lleva a la selección final de k variables regresoras entre el conjunto de variables que resultan candidatas, suele quedar retirado de la mirada del lector.
Este artículo apunta a visibilizar esta “trastienda” de la investigación3, buscando establecer, siempre que sea posible, cuánto de los resultados obtenidos se afectan según las decisiones tomadas en la investigación. El objetivo es allanar en algo el camino a quienes deban abordar por primera vez la información de ingresos personales relevada por la EPH mediante técnicas de descomposición de la varianza.
De entre todos los aspectos en que sería posible detenerse, nos referiremos a los tres ya mencionados: la especificación del modelo, el tratamiento de los casos con información faltante y la detección y tratamiento de los casos atípicos. Las reflexiones acerca de la especificación del modelo parten de la identificación de las variables que habitualmente se proponen como “explicativas” de la variabilidad salarial en la literatura especializada; luego se detalla el conjunto de variables consideradas como “candidatas” en nuestra investigación, para, posteriormente, presentar los resultados de la aplicación del método de introducción “paso a paso” de variables al modelo, que ponen en evidencia cuáles de esas variables (y en cuántos años de la serie) presentan una correlación estadística significativa con los salarios en presencia de las restantes; por último, se compara el R2 corregido correspondiente a los cuatro modelos finalmente aplicados.
El apartado siguiente refiere a la incidencia de la información faltante en los resultados obtenidos. Para ello, se parte de consideraciones generales acerca de la información faltante y sus medidas remediales; se continúa evaluando la incidencia y la fuente de la pérdida de información en las bases de datos utilizadas y, finalmente, se explicitan las limitaciones encontradas para aplicar medidas remediales adecuadas.
El tercer apartado trata sobre la detección y el tratamiento de los casos atípicos, partiendo de consideraciones generales acerca de estos casos en la regresión y el análisis factorial; en él se presenta una clasificación de los casos atípicos hallados en las veintiuna bases analizadas según su origen presunto y el tratamiento que se les aplicó. Por último, se evalúa la incidencia de las correcciones realizadas sobre los resultados de la regresión. Finalmente, se sintetizan las conclusiones principales.
2. La especificación del modelo
Existe una multitud de trabajos que, principal o subsidiariamente y desde perspectivas conceptuales diferentes, aplican técnicas basadas en la descomposición de la varianza (generalmente, la regresión múltiple) a la información sobre ingresos personales que surge de la la EPH, transformada mediante el cómputo del logaritmo natural4. Las variables incorporadas como regresoras varían de estudio en estudio, y conforman un conjunto que incluye el sexo de los perceptores, su nivel educativo, su condición de jefe de hogar, su edad, su edad al cuadrado, su estado civil, el número de hijos menores de 18 años, la categoría ocupacional, la condición de registro y la calificación de las ocupaciones, así como la rama de actividad, el sector y el tamaño de los establecimientos en que están empleados.
En nuestra investigación de Tesis, la identificación de las determinaciones principales del valor y el precio horario de la fuerza de trabajo nos llevó a seleccionar un conjunto de variables candidatas a formar parte de los modelos de regresión y de análisis factorial5. Una primera instancia del análisis de la información consistió en la exploración de las correlaciones parciales entre dichas variables y el logaritmo natural del salario horario, mediante el método “paso a paso” de introducción de variables.
Las variables candidatas fueron: el sexo; la edad; el sub-aglomerado de residencia (Ciudad de Buenos Aires o partidos del conurbano); la cantidad de menores de 18 años que habitan en el hogar del asalariado; el máximo nivel de instrucción alcanzado; la calificación de la ocupación; el carácter general de la ocupación; la situación de registro6; la antigüedad y la rama de actividad.
De antemano, este listado fue resultado de la exclusión de algunas variables que a primera vista parecían indicadores apropiados de ciertas determinaciones identificadas.
Para empezar, la variable correspondiente a la cantidad de menores de 18 años escolarizados que habitan en el hogar del asalariado fue excluida por dos razones. En primer lugar, por presumirse su colinealidad con la cantidad de menores de 18 años (escolarizados o no). En segundo lugar, en razón de que la inclusión en el salario mensual de un equivalente específico destinado a la educación de los hijos fue eliminada en 1996.
La exclusión de la “jerarquía ocupacional”, que sin duda presentaría correlación parcial con el salario, se debió al hecho de que sólo se encuentra disponible a partir del año 1992, año en que la codificación de la ocupación para el aglomerado GBA pasó a basarse en el Clasificador Nacional de Ocupaciones (CNO)7.
El “tamaño del establecimiento” en que el asalariado está empleado, por su parte, fue excluido debido a que, si bien la escala de operación del capital individual evidentemente juega un papel en la determinación del nivel del salario8, la información de la EPH que habitualmente se utiliza como indicador de este aspecto (v. gr., la cantidad de personas empleadas) resulta de utilidad limitada en este sentido9. Adicionalmente, se tuvo en consideración que los casos con información faltante para esta variable representaron el 11% de la muestra de asalariados de cada año del período 1985-2005, con un mínimo de 5% (en 1987) y un máximo de 22% (en 1990).
En síntesis, las variables candidatas a integrar el modelo de regresión fueron las que se detallan a continuación:
Cuadro 1: Variables candidatas para el modelo de regresión
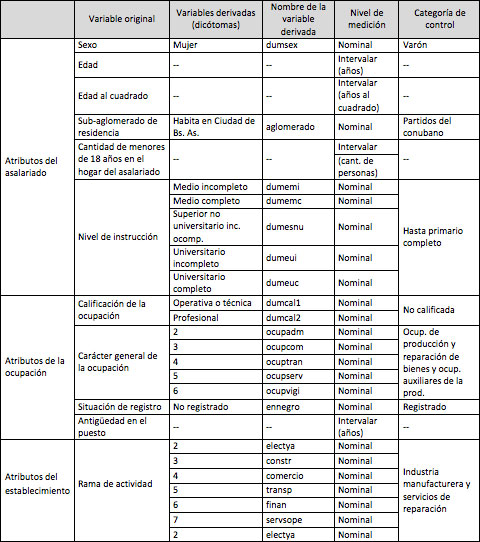
Carácter general de la ocupación:
1. Tareas de producción, auxiliares de producción y de reparación de bienes,
2. Tareas de gestión administrativa, jurídico-legal y contable (incluye tareas de dirección, véase nota 2),
3. Tareas de comercialización,
4. Tareas de transporte, almacenaje y telecomunicaciones,
5. Tareas de servicios,
6. Tareas de vigilancia y seguridad.
Rama de actividad:
1. Industria manufacturera y servicios de reparación.
2. Generación y distribución de electricidad, luz y agua.
3. Construcción.
4. Comercio al por mayor y menor y restaurantes y hoteles.
5. Transporte, almacenamiento y comunicaciones.
6. Intermediación financiera, servicios empresariales y de alquiler.
7. Servicios comunales, sociales y personales.
8. Sin dato y otras ramas de actividad.
El método “paso a paso” de introducción de variables regresoras al modelo10 conservó las variables correspondientes a la calificación de la ocupación, la antigüedad, la ocupación en tareas “de gestión administrativa, jurídico-legal y contable”,11 el máximo nivel educativo alcanzado por el asalariado (especialmente, los niveles iguales o superiores al medio completo) y la situación de registro del asalariado en todos los años en que el conjunto completo de las variables candidatas se encontraba presente (1986-1988 y 1991-2002)12.
Por su parte, la “cantidad de menores de 18 años en el hogar del asalariado” fue excluida por el proceso en catorce de los quince años observados. Las variables dicótomas referidas a las ocupaciones que involucraban tareas de transporte, almacenaje y telecomunicaciones y a las ramas de actividad ligadas con el transporte, el almacenamiento y las comunicaciones resultaron excluidas en trece y doce años, respectivamente, verificándose que su exclusión no se debía a su probable colinealidadrecíproca13. La variable dicótoma correspondiente a tareas “de servicios” fue excluida en diez años. Por su parte, las variables referidas a las ramas de “generación y distribución de electricidad, luz y agua”, “servicios sociales y personales” y “construcción” y las ocupaciones que involucraban “tareas de comercialización”, lo fueron en nueve.
En síntesis, las variables que aparecieron asociadas más fuertemente con la variabilidad del logaritmo del salario horario en presencia de las restantes fueron aquéllas ligadas con la complejidad del trabajo realizado, con el ejercicio de la representación del capital en la producción y la circulación y con la condición más o menos manifiesta de sobrante para las necesidades del capital total de la sociedad14. En cambio, el “carácter de la ocupación”, esto es, en un sentido muy general, el tipo de desgaste corporal que tiene lugar durante el trabajo15, no apareció jugando un papel en la determinación de diferencias salariales, a excepción de lo que sucedió con las tareas de “vigilancia y seguridad”, normalmente peor pagas que el resto. Por su parte, en las actividades de “comercio, restaurantes y hoteles” por lo general se pagaron los peores salarios, mientras que en las de “intermediación financiera, servicios empresariales y de alquiler” los salarios fueron más altos que en el resto en casi la mitad de los años aquí considerados. Fuera de éstas, tampoco la rama de actividad pareció establecer diferencias salariales sustanciales. Por último, el sexo, la edad, la edad al cuadrado, el sub-aglomerado de residencia y el nivel medio incompleto determinaron diferencias salariales significativas en la mayor parte de los años, si bien en general moderadas.
En nuestra investigación de tesis comparamos la bondad de ajuste de modelos diversos, especificados mediante la incorporación o la eliminación de variables individuales, a partir de un modelo básico aplicable a todos los años del período que se observó en la investigación. Así, al modelo que incluía las variables dicótomas derivadas de la calificación de la ocupación, el nivel educativo, la situación de registro, el sexo, la rama de actividad y el carácter de la ocupación y la edad, se incorporó primero el sub-aglomerado de residencia y luego la antigüedad en el puesto (quitándose entonces la edad, para prevenir una posible colinealidad). En un ejercicio posterior, se incorporó la edad al cuadrado a este último modelo.
Formalmente, los modelos quedaron especificados como se detalla a continuación:
Modelo 1:

Modelo 2:
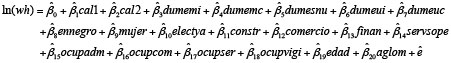
Modelo 3:
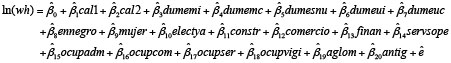
Modelo 4:
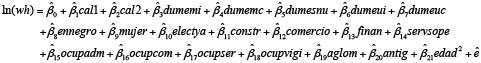
La comparación del R2 corregido muestra cómo mejora el ajuste de la función de regresión a medida que se incorporan el sub-aglomerado de origen, la antigüedad y la edad al cuadrado como variables regresoras (cuadro 2).
Cuadro 2: Bondad del ajuste de modelos de regresión (R2 corregido)* GBA. 1985-2005
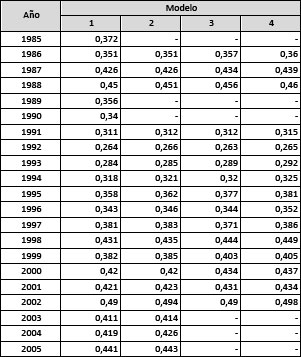
Nota (*) La información correspondiente al sub-aglomerado de residencia no se encuentra disponible en los años 1985, 1989 y 1990. De 2003 a 2005, la información correspondiente a la antigüedad en el puesto no fue publicada.
Como detallamos en el informe de tesis, la incorporación de la antigüedad en el puesto como variable regresora supone algunas diferencias de magnitud de los coeficientes de correlación parcial dignas de mención, con respecto a los modelos 1 y 2. Entre ellas, se encuentra: la reducción de la correlación parcial (positiva) entre el salario y las variables derivadas del nivel educativo, con la excepción del nivel universitario completo y la reducción del valor absoluto del coeficiente negativo de las variables “mujer” y “trabajador no registrado”.
En conclusión, nuestra investigación sugiere la pertinencia de centrar el análisis de la variabilidad del salario horario en su correlación con el máximo nivel de instrucción alcanzado, la calificación de la ocupación, el carácter general de la ocupación y/o la jerarquía ocupacional (según la extensión del período estudiado, debido a la disponibilidad de la segunda de estas variables), la antigüedad, la situación de registro, el sexo, la edad y la edad al cuadrado.
3. Los casos con información faltante
Little y Rubin señalan que “los paquetes estadísticos normalmente excluyen del análisis a aquellas unidades con código de no respuesta para alguna de las variables involucradas. Esta estrategia, tomada como regla general, es inapropiada, ya que lo que interesa al investigador es hacer inferencias sobre la población completa, más que sobre la porción que efectivamente responde a todas las variables relevantes en el análisis”16. Los análisis basados simplemente en las unidades completas son sencillos de desarrollar y pueden resultar apropiados cuando la cantidad de datos faltantes es pequeña aunque, como contrapartida, pueden derivar en sesgos en las en las estimaciones17.
Además del peso relativo de los casos con información faltante en la muestra, al evaluarse la pertinencia de aplicar medidas que remedien la pérdida de información, resulta relevante la consideración del mecanismo generador de la información faltante18. A éste se lo puede clasificar según su correlación con los valores de la variable dependiente o las independientes. Si la probabilidad de que un dato de Y se encuentre faltante es independiente tanto de los valores de Y como de los de X se dirá de los datos que se encuentran perdidoscompletamente al azar (PCA). Si, en cambio, dicha probabilidad depende de los valores de X pero no de los de Y,se dirá que están perdidos al azar (PA): los valores observados de Y no necesariamente serán una muestra aleatoria de los casos muestrales, pero sí de los valores que se encuentren dentro de las subclases definidas por los valores registrados de X. Si, por último la probabilidad de que un dato de Y se encuentre faltante depende de los valores de Y (y, posiblemente, también de los de X) el mecanismo generador de información faltante resulta no ignorable, en el sentido de que los análisis basados en los casos completos producirán necesariamente estimaciones sesgadas19.
Si los casos se encuentran perdidos completamente al azar, su ausencia no obsta para que se puedan realizar inferencias válidas a partir de los casos completos de la muestra. Cuando no puede suponerse que los datos perdidos son PCA pero sí PA, las técnicas disponibles para subsanar la existencia de casos con información faltante consisten en la alteración de la ponderación de las observaciones según la probabilidad de respuesta, por un lado, y la imputación de los valores perdidos, por otro. Cuando, en cambio, el mecanismo generador de información faltante es no ignorable, la estimación corregida debería basarse en la maximización de la verosimilitud para el conjunto de unidades respondentes y no respondentes, sobre la base de una modelización del mecanismo generador de información faltante, antes que en procedimientos que supongan la similitud de comportamiento entre unidades observadas y no observadas con respecto a la variable de interés. Aún entonces, el sesgo por no respuesta conserva un impacto potencialmente significativo, cuya dimensión depende de los valores que se asignen a los parámetros de la función de respuesta R (es decir, de la distribución condicionada de la probabilidad de respuesta efectiva20), los cuales por lo general no pueden ser fidedignamente estimados a partir de los datos. La solución óptima al problema de no respuesta no ignorable consiste en reducir la no respuesta o en acumular información acerca de cómo los no respondentes difieren de los respondentes en las variables respuesta bajo estudio.21 El seguimiento de unos pocos no respondentes puede ser de gran ayuda para la reducción de la sensibilidad de las inferencias22
Ha sido frecuentemente señalado que las encuestas de hogares encuentran dificultades para la correcta captación de los ingresos de los entrevistados23. El rechazo a responder la encuesta completa o la negativa a responder las preguntas relativas a los ingresos, generan una considerable pérdida de información. Al respecto, Beccaria y Herrero, citando a Minardi (2002), afirman que “luego de aparear hogares sin respuesta en una encuesta de Argentina con su respectiva cédula censal, la probabilidad de no respuesta a la encuesta aumenta en los hogares con características asociables a mayores ingresos familiares (cantidad de coberturas de salud, habitar viviendas grandes y ser propietario de vivienda y terreno)”24. Felcman, Kidyba y Ruffo (2003) señalan que la negativa a responder puntualmente la pregunta sobre ingresos laborales en la Encuesta Permanente de Hogares entre mayo de 1993 y mayo de 2002 se mostró “asociada a características particulares relacionadas con el ingreso”. En definitiva, se ha mostrado que, en la información de ingresos registrada mediante las encuestas de hogares en la Argentina, tanto la no respuesta total como la parcial resulta no ignorable.
De acuerdo con Felcman, Kidyba y Ruffo, el rechazo de encuesta completa afecta a alrededor del 15% de la muestra del total de aglomerados en las ondas comprendidas entre mayo de 1993 y mayo de 2002. La no respuesta parcial habría afectado, en el promedio del período, a entre el 6% y el 7% de los asalariados de todos los aglomerados relevados por la encuesta.25 En el caso de las muestras en que se basó nuestra investigación26, los asalariados encuestados que no declararon sus ingresos (no respuesta parcial) representaron un mínimo de 0% y un máximo de 16% de los asalariados entrevistados (ver cuadro 2, fila a). Adicionalmente, en especial durante la primera década considerada y en los dos últimos años de la segunda, hubo asalariados que, por diversas circunstancias, no percibieron ingresos en los treinta días previos a la realización de la encuesta. Este hecho incidió en la imposibilidad del cómputo del logaritmo natural de su salario horario y en que el software estadístico los considerara como “casos perdidos” para dicha variable. Estos casos representan entre el 0% y el 8% del total de asalariados encuestados durante el período (tabla 3, fila b). En total, los casos sin información relativa al logaritmo del salario horario representaron hasta un 21% de los asalariados encuestados, variando este porcentaje de acuerdo con el año (tabla 3, fila c).
Cuadro 3: Bondad del ajuste de modelos de regresión (R2 corregido)* GBA. 1985-2005
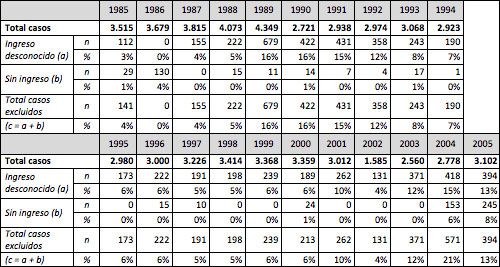
Otra fuente de distorsión de la información referida a ingresos proveniente de la EPH (y de las encuestas de hogares en general), consiste en la subdeclaración de los mismos. La probabilidad de subdeclaración también se encuentra relacionada con el nivel de ingresos del respondente . No contamos con una estimación de la proporción de subdeclaración que puedan presentar los ingresos de asalariados registrados por la EPH27, si bien cabe esperar que ésta no resulte digna de consideración28.
Puesto que un propósito principal de nuestra investigación de tesis era la estimación de los coeficientes de regresión y los tamaños de los efectos correspondientes a las variables independientes consideradas, los métodos de corrección de la no respuesta propuestos por Felcman, Kidyba y Ruffo no habrían resultado adecuados en el marco de la misma, aun cuando los datos perdidos hubieran sido PA. Su corrección de la no respuesta parcial (es decir, la no respuesta a la pregunta de ingresos) se basa en la imputación del ingreso individual a partir de un modelo econométrico que incluye características del trabajador, el establecimiento y el puesto de trabajo29. Esto es, a partir de las correlaciones parciales observadas que constituyeron el objeto mismo de nuestro estudio. Su corrección de la no respuesta total, por su parte, ajusta los ingresos de los perceptores ubicados en los cincuentiles superiores (en los que se concentran las diferencias entre la distribución de ingresos que surge de la información de EPH y la que tiene fuente en los registros del SIJP) de manera tal de compensar el efecto de la negativa a responder la encuesta completa por parte de hogares de ingresos altos30. La corrección, que puede ser apropiada cuando el objetivo final es realizar estimaciones de totales y medias generales de ingresos, resultaría aventurada en nuestro caso, en que se buscaba estimar la forma de la distribución multivariada y sus efectos sobre los diferenciales salariales entre grupos de trabajadores.
Puesto que la información referida a ingresos no se encuentra perdida al azar, las estimaciones obtenidas en nuestra investigación resultaron sesgadas y, por lo mismo, su extrapolación al conjunto de la población asalariada del aglomerado GBA no puede realizarse sin tomar en cuenta esta salvedad. La ausencia de los datos debería remediarse considerando la probabilidad individual de no respuesta (tanto total como parcial). El desafío pendiente consiste en modelizar esas probabilidades diferenciales. El seguimiento de un número al menos pequeño de no respondentes, si bien supone grandes dificultades, constituiría una herramienta invaluable para realizar dicha modelización.
4. Los casos atípicos
Un caso atípico dentro de un conjunto de datos es aquella “observación (o subconjunto de observaciones) que parece inconsistente con respecto al resto”31. El origen de tal comportamiento extraño puede deberse a circunstancias diversas: errores de declaración, transcripción o carga de la información, que genéricamente llamaremos “de medición”; inadecuación del modelo o la escala de medición32 escogidos para describir los datos; contaminación de la muestra por inclusión de individuos provenientes de una población diferente a la que se intentaba muestrear o, simplemente, inclusión en la muestra de casos cuya probabilidad de ocurrencia dada la distribución poblacional es baja, pero que aun así son expresión genuina de la variabilidad intrínseca de la población33.
Como es sabido, los procedimientos de maximización matemática -como los utilizados en nuestra investigación-, son especialmente sensibles a la presencia de observaciones que se separen considerablemente del resto o “atípicas”34. Si tales observaciones no resultaran ser miembros genuinos de la población principal, podrían contaminar severamente las estimaciones o pruebas de parámetros de la representación postulada35.
En los modelos multivariados, “un caso atípico […] puede distorsionar no sólo las medidas de posición o de escala, sino también aquéllas de orientación (es decir, la correlación)”36. En los diseños experimentales como ANOVA, la presencia de casos atípicos puede determinar la aparición de efectos significativos aparentes o encubrir efectos significativos reales al incrementar la suma de cuadrados del error.37 En la estimación de regresiones, los valores atípicos pueden, dependiendo de su ubicación en el espacio de X, afectar la altura promedio de la línea de regresión o sesgar la estimación de la pendiente.38
La detección de tales casos normalmente se basa en el examen de los efectos de la eliminación de una cantidad m de observaciones (generalmente una) por vez. En nuestra investigación, se realizó mediante el examen de la distancia de Cook y los valores DFFITS39.
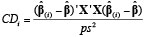 , mide el cambio en las estimaciones de los p parámetros cuando una observación es eliminada por vez. Cook y Weisberg (1982, citado en Stevens, 1986: 109), señalan que una
, mide el cambio en las estimaciones de los p parámetros cuando una observación es eliminada por vez. Cook y Weisberg (1982, citado en Stevens, 1986: 109), señalan que una  identifica puntos atípicos potencialmente influyentes. El estadístico que Belsleyet al. (1980, citado en Atkinson, 1997: 25) llamaron DFFITSi es una modificación del de Cook e indica cuánto cambiaría el iº valor predicho (
identifica puntos atípicos potencialmente influyentes. El estadístico que Belsleyet al. (1980, citado en Atkinson, 1997: 25) llamaron DFFITSi es una modificación del de Cook e indica cuánto cambiaría el iº valor predicho (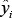 ) si la observación iª fuera eliminada. DFFITSi está dado por
) si la observación iª fuera eliminada. DFFITSi está dado por 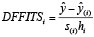
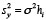 . De ahí que DFFITS indique la cantidad de desvíos estándar estimados en que cambia el valor ajustado cuando se elimina el punto iº (Stevens, 1986: 117). Se consideran dignos de atención aquellos casos en que
. De ahí que DFFITS indique la cantidad de desvíos estándar estimados en que cambia el valor ajustado cuando se elimina el punto iº (Stevens, 1986: 117). Se consideran dignos de atención aquellos casos en que 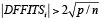
Frente a la presencia de casos atípicos, son habituales dos tipos de abordaje: 1) la utilización de una batería de técnicas de detección para su estudio detallado, con la posibilidad de excluir algunos o todos del análisis y 2) el desarrollo de procedimientos de estimación relativamente insensibles a los casos atípicos o “técnicas de regresión robusta”4041.
El tratamiento que se dé a los casos atípicos deriva de la identificación de la fuente que los produce. Por esto, Cook señala que, pese a que la detección de casos atípicos y el uso de métodos robustos aparecen compitiendo entre sí, ellos no constituyen abordajes mutuamente excluyentes42. La utilización a priori de técnicas de estimación robusta puede resultar en la pérdida de información valiosa que las observaciones que se alejan de la distribución esperada pueden brindar. En particular en nuestra investigación, la utilización de estimaciones robustas a la presencia de casos atípicos conllevaba el riesgo de subestimar la dispersión efectiva del salario horario.
De acuerdo con Barnett y Lewis, cuando se está frente a un error de medición obvio, la exclusión del caso extremo o su corrección están justificadas. En este caso, el procesamiento de la observación atípica no depende de análisis estadísticos, sino que debe emplearse el “ingenio nativo”43; la corrección no genera dificultades particulares y la realización de una prueba de discordancia resulta innecesaria44. Si el problema se encuentra en la representación propuesta o en la escala de medición de las variables involucradas, son ellas, evidentemente, las que deben ser corregidas. Cuando el caso atípico surge de la inclusión en la muestra de individuos de otra población, su detección podría derivar en la exclusión de los mismos, pero también dar lugar a un modelo modificado; por ejemplo, uno de carácter mixto o que contemplara fuentes de variabilidad no consideradas previamente45.
En nuestra investigación, sólo fueron tratados los casos atípicos detectados que resultaban atribuibles a errores de medición. Éstos se agruparon en ocho categorías no mutuamente excluyentes, según su origen presunto y los indicios principales en que se basó el diagnóstico. Existieron casos atípicos que reunían características correspondientes a más de una categoría; a éstos se los clasificó de acuerdo con la característica que se consideró más relevante para la inferencia de su origen. Los casos pertenecientes a un mismo grupo recibieron, por lo general, el mismo tipo de tratamiento, salvando pocas excepciones en las que la información disponible permitía o impedía conservar el caso en situaciones en que normalmente se lo hubiera excluido o conservado, respectivamente.
La investigación detectó ocho tipos básicos de casos atípicos producto de errores de medición. Estos son:
1) Incongruencia entre la duración declarada de la última jornada semanal y el monto del salario correspondiente a los últimos treinta días46, con la consiguiente distorsión del promedio salarial horario47. Estos casos fueron excluidos del análisis. Se dio igual tratamiento a los casos en que la escasa duración de la jornada semanal dificultaba la comparabilidad del salario horario con el del resto de los asalariados de la muestra.
2) Anomalías no especificadas, señaladas por el INDEC en la base de datos mediante el registro de ingresos iguales a cero en la variable correspondiente al ingreso total de fuente laboral de asalariados con una sola ocupación que, en cambio, mostraban datos en las variables correspondientes al ingreso mensual de la ocupación principal, la duración de la jornada semanal y y el ingreso horario de la ocupación principal (variable "inghora")48. Por tratarse de personas con sola ocupación, el ingreso total de fuente laboral debería haber sido coincidente con el de la ocupación principal. Este hecho, combinado con la discordancia que condujo a examinar el caso, nos llevó a excluir estos casos del análisis.
3) Declaración del ingreso correspondiente a períodos inferiores o superiores al mes, sin que esto fuera considerado en el cómputo del ingreso horario, con la consiguiente distorsión en el resultado. A raíz de la detección de estos casos, se corrigió el ingreso horario de todas las observaciones, a partir de la mensualización previa del monto de los ingresos49.
4) Probable declaración de la jornada semanal correspondiente a todas las ocupaciones y el ingreso correspondiente a una sola50, o viceversa51, en asalariados con más de una ocupación. En primera situación, se recalculó el ingreso horario a partir del monto declarado como ingreso total como asalariado (p47_1), si éste excedía del declarado como ingreso de la ocupación principal (p21); en la segunda, se excluyó el caso del análisis cuando no se disponía de información sobre la jornada semanal de las otras ocupaciones (bases 1985-1994) o si la consideración conjunta de la cantidad de ocupaciones y la diferencia entre ingresos como asalariado e ingreso de la ocupación principal no permitía establecer si todas las ocupaciones secundarias eran asalariadas.
5) Errores en la declaración/registro de la condición de registro o del ingreso de asalariados que declararon encontrarse plenamente registrados y cuyo ingreso mensual no se correspondía con el tipo de ocupación (calificación, jerarquía) que declaraban. Estos casos fueron, por lo general, excluidos del análisis52.
6) Inconsistencia de la información referida a la ocupación (distinta del ingreso). Por ejemplo, combinaciones incongruentes de dos o más de los siguientes atributos de los asalariados, sus ocupaciones y los capitales que los empleaban: nivel educativo, tamaño del establecimiento, rama de actividad, condición de registro, carácter de la ocupación, jerarquía, antigüedad en el puesto, jornada semanal53. Estos casos fueron excluidos del análisis sólo si el grado de inconsistencia así lo ameritaba.
7) Errores de carga en la variable correspondiente al ingreso mensual de la ocupación principal en individuos con una sola ocupación, detectados por comparación con el ingreso total de fuente laboral54. En estos casos, se reemplazó el valor del ingreso mensual con el del ingreso total y se recalculó el salario horario.
8) Errores diversos no correspondientes a ninguna de las categorías anteriores.
En la tabla 4 se resume la información referida, indicando el peso relativo de cada tipo de error con respecto al total de casos atípicos detectados en las veintiuna muestras sobre las que se trabajó.
Cuadro 4: Casos atípicos de regresión multivariada identificados en las bases de EPH onda octubre 1985-2002 y cuarto trimestre 2003-2005, según origen de la discordancia
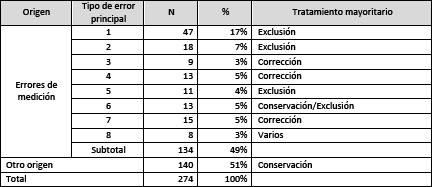
Los casos atípicos corregidos o eliminados representaron el 0,2% sobre el total de las observaciones de las veintiuna muestras utilizadas en la investigación.
La comparación de las series de coeficientes de correlación parcial según se corrija o no los casos discordantes debidos a errores de medición muestra que, pese a sus altos valores en el estadístico de Cook y en el DFFITS, la eliminación o corrección de estos casos no altera sustancialmente los resultados de la regresión (gráficos 1 a 19)55.
Lámina de gráficos 1: Coeficiente de regresión parcial para cada variable del modelo según corrección de errores detectados

Como puede apreciarse, el esfuerzo de “limpiar” las bases de datos mediante la eliminación de los datos discordantes identificados no parece justificarse, puesto que su presencia prácticamente no tiene efectos sobre los resultados obtenidos.
5. Conclusiones
De las lecturas citadas y los resultados encontrados, se deriva:
1) La conveniencia de construir los modelos de análisis de la varianza del salario horario en el GBA a partir de la inclusión de variables ligadas con: la complejidad del trabajo (“máximo nivel de instrucción alcanzado”, “calificación de la ocupación”), el ejercicio de la representación del capital (“carácter general de la ocupación” o “jerarquía ocupacional”), la adquisición de habilidades específicas para el puesto o el capital individual (“antigüedad”) y la manifiesta condición de sobrante para el capital total de la sociedad (“situación de registro”), el sexo, la edad y la edad al cuadrado. La inclusión de la antigüedad, particularmente, evita el sobredimensionamiento del valor absoluto de los coeficientes de correlación parcial de las variables derivadas del nivel educativo, del sexo y de la situación de registro, derivado de la probabilidad diferencial de obtener un puesto relativamente estable (y, por ende, de alcanzar una antigüedad mayor) de quienes cursaron niveles educativos superiores, de los varones y de los trabajadores registrados.
2) Que las estimaciones realizadas simplemente a partir del análisis de los casos con información completa resultarán sesgadas, dado que la información sobre ingresos no se halla perdida al azar. Un eventual seguimiento de un grupo de no respondentes aportaría información invaluable para la modelización de las probabilidades diferenciales de respuesta según el nivel de ingresos.
3) La irrelevancia de la influencia de los casos atípicos señalados por el estadístico de Cook y por el estadístico DFFITS que pueden atribuirse a errores de medición. Su eliminación o corrección no afectó sensiblemente las estimaciones obtenidas.
Como se refirió, entendemos que estos resultados pueden ser de utilidad para quienes, en lo sucesivo, aborden la tarea de estudiar los ingresos de la población del GBA mediante técnicas de descomposición de la varianza.
Bibliografía
ALTIMIR, O. y BECCARIA, L. (2001). “El persistente deterioro de la distribución del ingreso en la Argentina”, en Desarrollo Económico, vol. 40, Nº 160, IDES, Buenos Aires.
ALTIMIR, O. (1986). “Estimaciones de la Distribución del Ingreso en la Argentina, 1953-1980”, en Desarrollo Económico, vol. 25 N° 100, IDES, Buenos Aires.
ALTIMIR, O., BECCARIA, L, GONZÁLEZ ROZADA, M. (2002). “La distribución del ingreso en Argentina, 1974-2000”, en Revista de la CEPAL Nº 78, Chile.
ATKINSON, A. C. (1997). Plots, transformations and regression. An introduction to graphical methods of diagnostic regression analysis, Oxford Statistical Science Series, Oxford University Press, Oxford.
BARNETT, V. y LEWIS, T. (1978). Outliers in statistical data, John Wiley & Sons Ltd., Bath.
BECCARIA, L. y HERRERO, D. (2003). “La medición de los ingresos relacionados con el empleo en las encuestas de hogares”, en Taller del MECOVI (Programa para el mejoramiento de las encuestas y la medición de las condiciones de vida en América Latina y el Caribe), (12: 2003: Buenos Aires), MECOVI, disponible en http://www.eclac.cl/deype/mecovi/taller12.htm en diciembre de 2007.
CAMELO, H. (1998). “Subdeclaración de ingresos medios en las encuestas de hogares, según quintiles de hogares y fuentes de ingreso”, en Taller Regional de Medición del Ingreso en las Encuestas de Hogares (2º: 1998: Buenos Aires), MECOVI, disponible en www.eclac.cl/deype/mecovi/docs/TALLER2/30.pdf en diciembre de 2007.
COOK, R. D. y WEISBERG, S. (1982), Residuals and influence in regression, Chapman & Hall, Nueva York.
DANIEL, C. y WOOD, F. S. (1971). Fitting equations to data, Wiley, Nueva York.
FARFÁN, M. G. y RUIZ DÍAZ, M. F. (2007). Discriminación salarial en la Argentina: un análisis distributivo, Documento de Trabajo N° 60, CEDLAS, La Plata.
FELCMAN, D, KIDYBA, S, y RUFFOM H. (2003). “Medición del ingreso laboral: Ajustes a los datos de la Encuesta Permanente de Hogares para el análisis de la distribución del ingreso (1993 - 2002)”, en Reunión Anual (38º: 2003: Mendoza), Asociación Argentina de Economía Política, disponible en http://www.aaep.org.ar/anales/works/works2003/Felcman_Kidyba_Ruffo.pdf en septiembre de 2006.
GNANADESIKAN, R. y KETTENRING, J. R. (1972), “Robust estimates, residuals and outlier detection with multiresponse data”, en Biometrics, vol. 28.
GROISMAN, F. (2001). “Determinantes del salario en el mercado de trabajo urbano argentino. Una aproximación al fenómeno de devaluación educativa”, en Congreso Nacional de Estudios del Trabajo, (5º: 2001: Buenos Aires), Asociación Argentina de Especialistas en Estudios del Trabajo.
HERRERO, D. (2001). Comparación armonizada de las estimaciones de población e ingresos del SIJP y la EPH. Sector privado del Gran Buenos Aires, ingresos devengados /percibidos en agosto /septiembre de 1997, Serie Metodologías, INDEC-MECOVI, Buenos Aires.
IÑIGO, L. (2010). Escolaridad y diferenciación de la fuerza de trabajo en el Gran Buenos Aires, 1985-2005, Tesis de Maestría, inédita.
JOHNSON, R. A. y Wichern, D. H. (1982). Applied Multivariate Statistical Analysis, Prentice-Hall, Englewood Cliffs.
LITTLE, R. y RUBIN, D. (1987). Statistical analysis with missing data, John Wiley & Sons, Inc., Nueva York.
LLACH, J. J. y MONTOYA, S. (1999). En pos de la equidad. La pobreza y la distribución del ingreso en el área metropolitana de Buenos Aires: diagnóstico y alternativas políticas, IERAL, Buenos Aires.
MARX, C. (1997). El capital. Crítica de la economía política, tomo III (13ª Ed.), Siglo Veintiuno Editores, México D.F.
MAURIZIO, R. (2001). “Demanda de trabajo, sobreeducación y distribución del ingreso”, en Congreso Nacional de Estudios del Trabajo (5º: 2001: Buenos Aires), Asociación Argentina de Especialistas en Estudios del Trabajo.
MINARDI, G. (2002). Informe final Proyecto MECOVI: Calidad en encuestas a hogares, MECOVI, Buenos Aires.
ROCA, E. y PENA, H. (2001). “La declaración de ingresos en las encuestas de hogares”, Estudios del Trabajo Nº 22, ASET, Buenos Aires.
STEVENS, J. (1986). Applied Multivariate Statistics for the Social Sciences, Lawrence Erlbaum Associates Publishers, New Jersey.
WAISGRAIS, S. (2005). “Determinantes de la sobreeducación de los jóvenes en el mercado laboral argentino”, en Congreso Nacional de Estudios del Trabajo, Buenos Aires (7º: 2005: Buenos Aires). Asociación Argentina de Especialistas en Estudios del Trabajo.
RAESTA 3 - Año 3 (2016)
Presentación
Artículos
Desempeño de las PyME industriales argentinas, 2005-2011: Medición de eficiencia en la producción a través de un enfoque no-paramétrico. +Laura MastroscelloAnálisis multivariado aplicado a la generación de escenarios complejos en torno a concepciones de sexualidad y género en alumnos de escuelas medias. +Sebastián Ezequiel SustasLucas KlobovsLiliana Pascual“El análisis de redes sociales como herramienta para focalizar la intervención en entornos rurales a través de políticas públicas. +Nicolás Vladimir Chuchco / Cintia Noelia Díaz / María Leonor Pérez BrunoNicolás Sacco
RAESTA 2 - Año 2 (2015)
Editorial
Artículos
Bruno De SantisConstrucción de un índice del nivel socioeconómico del hogar urbano en la República Argentina mediante el análisis de correspondencia múltiple y escalamiento óptimo. +María Fernanda Artola / Iván Redini BlumenthalOrientaciones de futuro laboral y educativo de estudiantes secundarios. Análisis multivariado en un diseño muestral complejo. +Rosario AustralMarcelo Bergman / Diego Masello / Christian Arias / Guadalupe Peralta AgüeroUn ejemplo de diseño cuasi experimental: uso de la regresión logística binaria en la construcción de un grupo de comparación para la evaluación de impacto de un programa social. +Horacio ChitarroniMetodología estadística para la estimación de las superficies sembradas con cultivos extensivos - método de segmentos aleatorios. +Norberto V. Rodríguez / Julieta Mirensky
RAESTA 1 - Año 1 (2014)
Editorial
Artículos
La pérdida de valor de las credenciales educativas en el mercado de trabajo Argentino 1995-2001. Una respuesta desde los métodos estadísticos. +Florencia SourrouilleLos docentes en la Encuesta Permanente de Hogares. Notas metodológicas para su identificación y estudio. +Leandro BottinelliEspecificación del modelo, datos faltantes y casos atípicos: la “trastienda” de una investigación basada en el análisis de la varianza. +Luisa IñigoAna María Capuano